二进制与数字
在古代,曾经使用的通信方式是使用烽火台,一旦出现战事,有敌人发起攻击,则会点燃烽火用烟来传递信息。因为光信号的传递速度很快,所以古代的这种信息传递方式是非常高效的。假设长城足够长的话,通过烽火依次传递消息,能很快的传递信息给盟友。点火代就表敌人来了,不点火则代表没有敌人。但是这种信息传递方式有一个缺点,那就是无法精确传递敌人的规模。
假设敌人有十万大军,这时候应该怎样向盟军传递信息呢?如果点燃一根火把来代表一个敌人,则没有办法在短时间内表示十万;于是可以点燃一根火把来代表敌人规模是 1~100,再点燃第二根则代表敌人规模是 101~1000,点燃第三根则代表敌人规模是 1001~5000 。以此类推:
如果需要精确传递敌人的个数,这种方法就不可行了。火把只有亮和灭两种状态,那么如何才能表示精确的数字呢?
既然一根火把可以表示两个状态,那么两根火把便可以表示四个状态。三根火把便可以表示八个状态。因此我们就可以约定,第一根火把亮了代表 1(2 的 0 次幂),第二根火把亮了代表2(2 的 1 次幂),第三根火把亮了代表 4(2 的 2 次幂),不亮的位置代表的就是 0 。那么对于位置 n 的火把,他亮了就代表 2^(n-1) 。因此,可以通过以下的方式来表示精确数值:
从右向左,第一根火把亮代表 2^(1-1)=1,第二根火把灭代表 0,那么代表的敌人数量就是 2^(1-1) + 0 = 1 :

从右向左,第一根火把灭代表 0 ,第二根火把亮代表 2^(2-1)=2,那么代表的敌人数量就是 0 + 2^(2-1) = 2 :

从右向左,第一根火把亮代表 2^(1-1)=1,第二根火把亮代表 2^(2-1)=2,那么代表的敌人数量就是 2^(1-1) + 2^(2-1) = 3 :

从右向左,第一、二根火把灭都代表 0 ,第三根火把亮代表 2^(3-1)=4,那么代表的敌人数量就是 0 + 0 + 2^(3-1) = 4 :
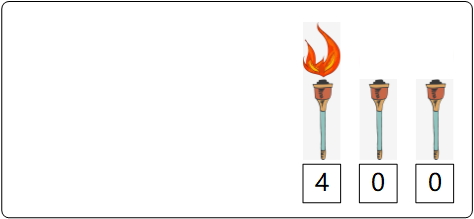
从右向左,第一根火把亮代表 2^(1-1)=1,第二根火把灭代表 0,第三根火把亮代表 2^(3-1)=4,那么代表的敌人数量就是 2^(1-1) + 0 + 2^(3-1) = 5 :
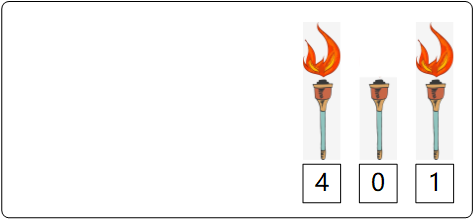
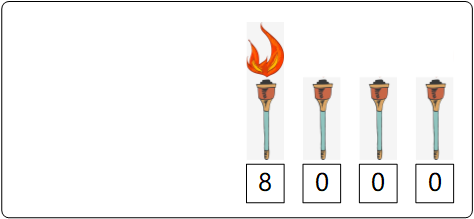
按照这样的方式来表示,我们发现利用前三位可以表示的数字有 0、1、2、3、4、5、6、7,最多能表示 7 。如果想要表示 8,我们可以再借一个位置,即第四个位,用这个位加上前面的三个位来表示 8 : 0 + 0 + 0 + 2^(4-1) = 8 :
利用这种表示方法,我们就可以使用 0 代表火把灭,使用 1 代表火把亮,从而就会有不同序列,来表示不同的数字:
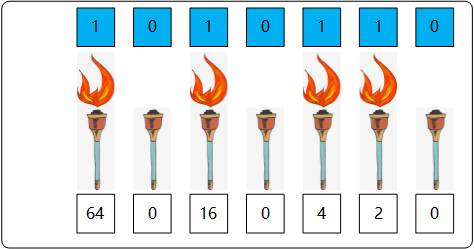
上图中用 0 和 1 表示出来的序列就是 1010110,那么他所表示的数字就是 0 + 2^1 + 2^2 + 0 + 2^4 + 0 + 2^6 即 0 + 2 + 4 + 0+ 16 + 0 + 64 = 86。
计算机必须在通电情况下工作,它在物理层面上只能表示两种状态:低电压和高电压,或者可以简单地理解为电路的通电和不通电。通电用 1 表示,不通电则用 0 表示。在拆开的硬盘盘片上我们看不到所谓的 0 和 1 ,但是如果使用足够大的放大镜,则能看到磁盘的表面有着无数的凹凸不平的元件,凹下去的代表 0 ,凸出的代表 1,这就是计算机用来表现二进制的方式。计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上最终都是按照类似 01010101 的二进制存储的。
ASCII码
通过二进制的 1 和 0 的不同序列边就可以表示平常所说的十进制数字了,但是每个国家都有各自的语言,相比在计算机上去读很难读懂的不同序列的 0101 二进制,我们更愿意在计算机上使用人类自己的语言。
计算机诞生在美国,为了让计算机表示不同的英文字母、数字和特殊符号,美国人便在计算机上使用了字符编码。字符编码是如何让二进制来表示字母的呢?字符编码专门规定了哪些数字表示哪些字母,只要计算机用二进制能表示出这些数字,便可以通过编码来表示字母了。
比如计算机中是用二进制 01000001 表示的十进制数字是 65,那么人就规定数字 65 代表大写字母 A:

以此类推,所有的人为规定就形成了一张对照表,最早的编码便是 ASCII 码对照表,全称是 American Standard Code for Information Interchange , 美国信息交换标准代码。ASCII 码使用指定的 7 位或 8 位二进制数组合来表示128 或 256 种可能的字符,但是最早的时候只用了 7 位二进制,已经完全能够来表示所有的大写和小写字母,数字 0 到 9、标点符号, 以及在美式英语中使用的特殊控制字符。后来为了将拉丁文也编码进了 ASCII 表,将最高位也占用了,这就是扩展 ASCII 码。
| 二进制 | ASCII值 | 控制字符 | 二进制 | ASCII值 | 控制字符 | 二进制 | ASCII值 | 控制字符 | 二进制 | ASCII值 | 控制字符 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 00000000 | 0 | NUT | 00100000 | 32 | (space) | 01000000 | 64 | @ | 01100000 | 96 | 、 |
| 00000001 | 1 | SOH | 00100001 | 33 | ! | 01000001 | 65 | A | 01100001 | 97 | a |
| 00000010 | 2 | STX | 00100010 | 34 | “ | 01000010 | 66 | B | 01100010 | 98 | b |
| 00000011 | 3 | ETX | 00100011 | 35 | # | 01000011 | 67 | C | 01100011 | 99 | c |
| 00000100 | 4 | EOT | 00100100 | 36 | $ | 01000100 | 68 | D | 01100100 | 100 | d |
| 00000101 | 5 | ENQ | 00100101 | 37 | % | 01000101 | 69 | E | 01100101 | 101 | e |
| 00000110 | 6 | ACK | 00100110 | 38 | & | 01000110 | 70 | F | 01100110 | 102 | f |
| 00000111 | 7 | BEL | 00100111 | 39 | , | 01000111 | 71 | G | 01100111 | 103 | g |
| 00001000 | 8 | BS | 00101000 | 40 | ( |
01001000 | 72 | H | 01101000 | 104 | h |
| 00001001 | 9 | HT | 00101001 | 41 | ) |
01001001 | 73 | I | 01101001 | 105 | i |
| 00001010 | 10 | LF | 00101010 | 42 | * |
01001010 | 74 | J | 01101010 | 106 | j |
| 00001011 | 11 | VT | 00101011 | 43 | + |
01001011 | 75 | K | 01101011 | 107 | k |
| 00001100 | 12 | FF | 00101100 | 44 | , | 01001100 | 76 | L | 01101100 | 108 | l |
| 00001101 | 13 | CR | 00101101 | 45 | - | 01001101 | 77 | M | 01101101 | 109 | m |
| 00001110 | 14 | SO | 00101110 | 46 | . | 01001110 | 78 | N | 01101110 | 110 | n |
| 00001111 | 15 | SI | 00101111 | 47 | / | 01001111 | 79 | O | 01101111 | 111 | o |
| 00010000 | 16 | DLE | 00110000 | 48 | 0 | 01010000 | 80 | P | 01110000 | 112 | p |
| 00010001 | 17 | DCI | 00110001 | 49 | 1 | 01010001 | 81 | Q | 01110001 | 113 | q |
| 00010010 | 18 | DC2 | 00110010 | 50 | 2 | 01010010 | 82 | R | 01110010 | 114 | r |
| 00010011 | 19 | DC3 | 00110011 | 51 | 3 | 01010011 | 83 | S | 01110011 | 115 | s |
| 00010100 | 20 | DC4 | 00110100 | 52 | 4 | 01010100 | 84 | T | 01110100 | 116 | t |
| 00010101 | 21 | NAK | 00110101 | 53 | 5 | 01010101 | 85 | U | 01110101 | 117 | u |
| 00010110 | 22 | SYN | 00110110 | 54 | 6 | 01010110 | 86 | V | 01110110 | 118 | v |
| 00010111 | 23 | TB | 00110111 | 55 | 7 | 01010111 | 87 | W | 01110111 | 119 | w |
| 00011000 | 24 | CAN | 00111000 | 56 | 8 | 01011000 | 88 | X | 01111000 | 120 | x |
| 00011001 | 25 | EM | 00111001 | 57 | 9 | 01011001 | 89 | Y | 01111001 | 121 | y |
| 00011010 | 26 | SUB | 00111010 | 58 | : | 01011010 | 90 | Z | 01111010 | 122 | z |
| 00011011 | 27 | ESC | 00111011 | 59 | ; | 01011011 | 91 | [ | 01111011 | 123 | { |
| 00011100 | 28 | FS | 00111100 | 60 | < | 01011100 | 92 | / | 01111100 | 124 | |
| 00011101 | 29 | GS | 00111101 | 61 | = | 01011101 | 93 | ] | 01111101 | 125 | } |
| 00011110 | 30 | RS | 00111110 | 62 | > | 01011110 | 94 | ^ | 01111110 | 126 | ` |
| 00011111 | 31 | US | 00111111 | 63 | ? | 01011111 | 95 | _ | 01111111 | 127 | DEL |
字符编码的发展史
计算机开始普遍在其他国家开始使用,但是 ASCII 只能表示英文,无法表示中文、日文、韩文等。一个字节是 8 个比特,这意味着 1 个比特并没有被使用,也就是从 128 到 255 的编码并没有被制定 ASCII 标准的人所规定。其它国家的人趁这个机会开始使用 128 到 255 范围内的编码来表达自己语言中的字符。例如,144 在阿拉伯人的 ASCII 码中是 گ,而在俄罗斯的 ASCII 码中是 ђ。ASCII 码的问题在于尽管所有人都在 0-127 号字符的使用上达成了一致,但对于 128-255 号字符却有很多很多不同的解释。你必须告诉计算机使用哪种风格的 ASCII 码才能正确显示 128-255 号的字符。
中文编码
为了处理汉字,程序员设计了用于简体中文的 GB2312 和用于繁体中文的 big5 。GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。
GB2312 支持的汉字太少。1995年的汉字扩展规范 GBK1.0 收录了 21886 个符号,它分为汉字区和图形符号区。汉字区包括 21003 个字符。2000年的 GB18030 是取代 GBK1.0 的正式国家标准。该标准收录了 27484 个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的 PC 平台必须支持 GB18030,对嵌入式产品暂不作要求。所以手机、MP3 一般只支持 GB2312。
从 ASCII、GB2312、GBK 到 GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK 到 GB18030 都属于双字节字符集 (DBCS)。
有的中文 Windows 的缺省内码还是 GBK,可以通过 GB18030 升级包升级到 GB18030。不过 GB18030 相对 GBK 增加的字符,普通人是很难用到的,通常我们还是用 GBK 作为中文 Windows 系统的缺省编码。
Unicode
全世界有上百种语言,日本把日文编到 Shift_JIS 里,韩国把韩文编到 Euc-kr 里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。比如如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有 GBK 编码。
因此,Unicode(统一码、万国码、单一码)应运而生。Unicode 把所有语言都统一到一套编码里,这样就不会再有乱码问题了。规定所有的字符和符号统一最少由 16 位(2Bytes)代表一个字符,2**16-1=65535,可代表6万多个字符,因而兼容万国语言。
UTF-8
但对于通篇都是英文的文本来说,本来用一个字节就可以表示的内容,用 Unicode 这种编码方式无疑是多了一倍的存储空间。本着节约的精神,于是产生了 UTF-8,对英文字符只用 1Bytes 表示,对中文字符用 3Bytes 。如果要传输的文本包含大量英文字符,用 UTF-8 编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| ‘A’ | 01000001 | 00000000 01000001 | 01000001 |
| ‘中’ | 无法表示 | 01001110 00101101 | 11100100 10111000 10101101 |
总结:
为了处理英文字符,产生了 ASCII 码。为了处理中文字符,产生了 GB2312。
为了处理各国字符,产生了 Unicode 。在 Unicode 中所有字符都是 2Bytes,兼容所有语言字符,优点是字符 => 数字的转换速度快,缺点是占用空间大。
为了提高 Unicode 存储和传输性能,产生了 UTF-8,它是 Unicode 的一种实现形式,对于不同的字符用不同的长度表示,优点是节省空间,缺点是:字符 => 数字的转换速度慢,因为每次都需要计算出字符需要多长的 Bytes 才能够准确表示。
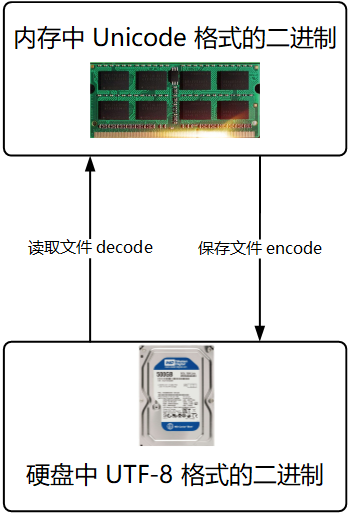
内存中使用的编码是 Unicode:用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)。
硬盘中或者网络传输用 UTF-8:网络 I/O 的延迟或磁盘 I/O 的延迟要远大与 UTF-8 的转换延迟,而且 I/O 应该是尽可能地节省带宽,保证数据传输的稳定性。
编码的使用
计算机中所有程序的运行都是在内存中进行的。内存 ( Memory ) 也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来。
当我们在计算机上打开一个文本编辑器的时候,计算机实际上就是在内存中启动了一个相应的进程,所以我们所有编辑的内容也都在内存中存放,只有当我们点击保存的时候才会将数据写入硬盘,没有保存之前一旦断电,内存中未保存的数据就会丢失。
在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要传输的时候,就转换为 UTF-8 编码。需要注意的是 文件以什么编码方式保存的,就以什么编码方式打开。
Python的编码
普通文件的编码
1 | python test.py |
如上所示的,一个在命令行使用 Python 解释器来执行写好的 Python 程序文件,整个过程大致可以分成三个步骤:
- 启动解释器,进程运行在内存中。
- 解释器将
test.py从硬盘读入内存,读入文件内容到内存时用的编码方式和文件保存时用到的编码是一样的。 - 解释器执行内存中的代码。
当我们在 windows 创建一个记事本文件 notepad.txt,写入以下内容:
1 | Python是一种计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。 |
保存后传到一台系统编码格式为 UTF-8 的 Linux 服务器上。使用 cat 命令查看文件时出现了乱码,得到的是如下结果:
1 | Pythonһhell)Խ |
这是因为,在 Linux 中常见例如 cat、head 、vim 等命令在读取硬盘中的文件、往硬盘上写入文件时默认用的是系统环境的 UTF-8 编码。而从 Windows 下拷贝过来的文件是以 gbk 编码的二进制,编码不一致导致出现乱码。
Python代码文件头部的编码
默认情况下,Python 源码文件是以 UTF-8 编码方式来处理的。在这种编码方式中,世界上绝大多数语言的字符都可以同时用于字符串字面值、变量或函数名称以及注释中。
如果不使用默认编码,要对 Python 解释器声明处理源码文件时所使用的编码,文件第一行或第二行要写成特殊的注释。语法如下所示:
1 | # -*- coding:utf-8 -*- |
这一行就告诉了 Python 解释器以 utf-8 的编码处理当前文件的代码。通常情况下我们要想让 Python 脚本可以直接执行,就像 shell 脚本一样,第一行添加:
1 | #!/usr/bin/env python3 |
这种情况下,编码声明就要写在文件的第二行。例如:
1 | #!/usr/bin/env python3 |
当我们在 Python 源码文件中用了中文字符作为字面值时,如果文件头部声明的是日文的字符编码 Shift_JIS:
1 | #!/usr/bin/env python3 |
当 Python 解释器处理代码时就会因为无法识别中文的编码就会出现编码问题:
1 | $ python3 test.py |
为了说明问题,我们在 Python 代码中使用中文字符作为函数名、参数,如果文件头部声明的是西欧字符编码 Windows-1252:
1 | #!/usr/bin/env python3 |
当 Python 解释器处理代码时就会因为无法识别中文的编码出现乱码:
1 | $ python3 test.py |
将源码文件中的 Windows-125 改为 utf-8 后,Python 解释器便可以成功处理代码:
1 | $ python3 test.py |
由此可见,在 Python 源码文件首部的编码声明对 Python 解释器起着至关重要的作用。在 Python 标准库中只用常规的 ASCII 字符作为变量或函数名,对于编写任何可移植的代码,我们都应该遵守此约定。要正确显示这些字符,你的编辑器必须能识别 UTF-8 编码,而且必须使用能支持打开文件中所有字符的字体。
Python内置方法的编码
在 Python 代码中对于内置方法 open() 操作文件时,在文本模式下,如果 encoding 没有指定,则根据操作系统的平台来决定使用的编码,如果要读取和写入原始字节,请使用二进制模式并且不要指定 encoding。
对于字符串类型的 encode() 方法和 bytes 类型的 decode() 方法,处理标准流(标准输出、标准输入、标准错误输出)等,默认都使用 UTF-8 作为编码。
例如:
1 | s = '你好' |
请一定要注意,这里说的编码和 Python 源码文件首部的编码不是一回事,一个是内置方法用什么样的编码处理对象,而另一个说的是 Python 解释器是以什么样的编码执行代码。
对于在上面说到的在 Windows 下创建的记事本文件 notepad.txt,如果在 Python 中使用 open() 方法不指定 encoding 则默认使用 Linux 系统的 UTF-8 作为编码:
1 | #!/usr/bin/env python3 |
执行后报错:
1 | UnicodeDecodeError: 'utf-8' codec can't decode byte 0xca in position 6: invalid continuation byte |
这是因为文件 notepad.txt 在 Windows 中是以 GBK 编码编辑文件和保存的,到了 Linux 上用 UTF-8 无法打开 GBK 编码的文件,必须使用 GBK 才能正确打开,所以应该为 open() 方法指定 GBK 作为编码方式:
1 | #!/usr/bin/env python3 |
为了彻底解决这个乱码的问题,我们应该将正确读到的文件再以 UTF-8 的编码方式写入硬盘:

由于不能同时对一个文件对象进行又读又写的操作,所以应将读入内存的内容重新写到另外一个新的文件,最后对文件重命名即可。具体操作代码如下:
1 | #!/usr/bin/env python3 |
这时再使用 cat 查看文件内容就不会再有乱码了。
而对于原本在 Windows 上创建的记事本文件 notepad.txt,在 Windows 下使用 Python 解释器来处理也是用的 utf-8 ,为什么没有出现乱码呢? 这其实是 Windows 里的某个程序帮你处理了,而 Linux 下没有使用其他程序进行处理,所以会出现乱码问题。
内存中的执行
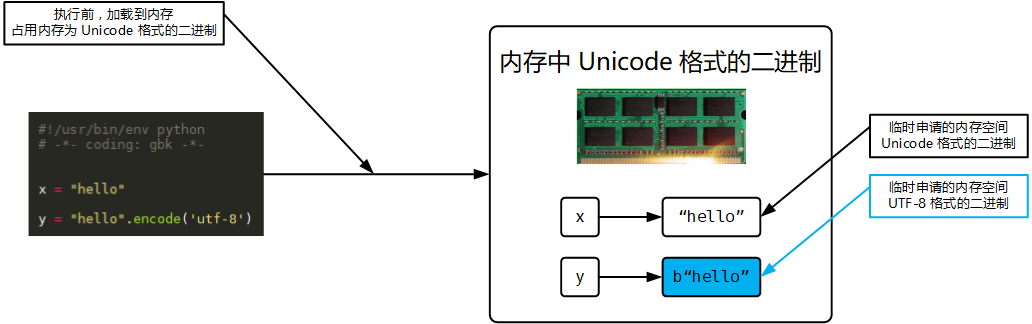
Python 读取已经加载到内存的代码(unicode 编码的二进制),然后执行,在执行过程中可能会开辟新的内存空间,比如 x="hello"
内存的编码使用 unicode,不代表内存中全都是 unicode 编码的二进制,在程序执行之前,内存中确实都是 unicode 编码的二进制,比如从文件中读取了一行 x="hello" ,其中的 x,等号,引号,地位都一样,都是普通字符而已,都是以 unicode 编码的二进制形式存放于内存中的。但是程序在执行过程中,会申请内存(与程序代码所存在的内存是两个空间),可以存放任意编码格式的数据,比如 x="hello" ,会被 Python 解释器识别为字符串,会申请内存空间来存放字符串 hello,然后让 x 指向该内存地址,此时新申请的该内存地址保存也是 unicode 编码的 hello ,如果代码换成 x="hello".encode('utf-8'),那么新申请的内存空间里存放的就是 utf-8 编码的字符串 hello 了.
str 与 bytes
在 Python3 中有两种字符类型 str 和 bytes ,并且在 Python3 以后,这两种类型彻底分开了。
str 类型以字符为单位进行处理,在内存中默认以 unicode 编码保存到新的内存空间中。
1 | s = '好' # 当程序执行时,无需加 u,默认以 unicode 形式保存新的内存空间中 |
bytes 类型是以字节为单位处理,在所有的操作和使用甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象。
bytes 对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定。Python3 中 bytes 通常用于网络数据传输、二进制图片和文件的保存等等。
1 | s = '好' # 当程序执行时,无需加 u,默认以 unicode 形式保存新的内存空间中 |
我们可以通过调用内置的方法 bytes() 生成 bytes 实例,其值的形式为 b'xxxxx',其中 'xxxxx' 为一到多个转义的十六进制字符串(单个 x 的形式为 \x12,其中 \x 为小写的十六进制转义字符,12 为二位十六进制数)组成的序列,每个十六进制数代表一个字节(八位二进制数,取值范围 0-255),对于同一个字符串如果采用不同的编码方式生成 bytes 对象,就会形成不同的值。
1 | #!/usr/bin/env python3 |
总结
在 ASCII 中一个中文字符占用几个字节?答:ASCII无法表示中文字符。
Python2 的默认文件编码是 ascii。Python3 的默认文件编码是 utf-8,所有字符串都是 unicode。unicode 中一个中文占用两个字节空间,utf-8 中一个中文占用三个字节
当数据要打印到终端时,要注意的问题: 当程序执行时,比如: x = '好';print(x) ,这一步是将 x 指向的那块新的内存空间(非代码所在的内存空间)中的内容打印到终端,而终端仍然是运行于内存中的,所以这打印可以理解为从内存打印到内存,即内存 => 内存,unicode => unicode,对于 unicode 格式的数据来说,无论怎么打印都不会乱码。
参考链接:
https://www.cnblogs.com/vipchenwei/p/6993788.html
http://blog.csdn.net/apache0554/article/details/53889253

