字符串
Python 字符串不可以被更改,它们是不可变的 。因此,赋值给字符串索引的位置会导致错误。字符串是使用固定不变的 str 数据类型表示的,其中存放 Unicode 字符序列。 str 数据类型可以作为函数进行调用,用于创建字符串对象:
参数为空时返回一个空字符串,例如
x = str();参数为非字符串类型时返回该参数的字符串形式,例如
x = str(3);参数为字符串时返回该字符串的拷贝,例如
x = str('Hello')。
str() 函数也可以用作一个转换函数,此时要求第一个参数为字符串或可以转换为字符串的其他数据类型,其后跟随至多两个可选的字符串参数,其中一个用于指定要使用的编码格式,另一个用于指定如何处理编码错误。
引号的使用
字符串是使用引号创建的,可以使用单引号也可以使用双引号,但是字符串两端必须相同。此外还可以使用三引号包含的字符串——这是 Python 对起始端与终端都使用3个引号包含的字符串的叫法,例如:
1 | text = """A triple quoted string like this can include 'quotes' and |
如果需要在通常的、引号包含的字符串中使用引号,在要使用的引号与包含字符串的引号不同时,可以直接使用该引号,而不需要进行格式化处理操作,但是如果相同,就必须对其进行转义:
1 | a = "Single 'quotes' are fine; \"doubles\" must be escaped." |
换行
Python 使用换行作为其语句终止符,但是如果在圆括号、方括号、花括号内或三引号包含的字符串内则是例外。在三引号包含的字符串中,可以直接使用换行而不需要进行格式化处理操作。通过使用 \n 转义,也可以在任何字符串中包含换行。
有些情况下——比如编写正则表达式时, 需要创建带有大量字面意义反斜杠的字符串。由于每个反斜杠都必须进行转义处理,从而造成了不便:
1 | import re |
解决方法是使用原始的字符串,这种引号包含的或三引号包含的字符串的第一个引号由字面意义的 r 引导。在这种字符串内部,所有字符都按其字面意义理解,因此不再需要进行转义。下面给出了使用原始字符串的 phone 正则表达式:
1 | phone2 = re.compile(r"^((?:[()\d+[]])?\s*\d+(?:-\d+)?)$") |
再比如:
1 | print('C:\some\name') # 这里的\n意味着换行 |
如果变量中有特殊字符串,但不希望被引用,则可以使用 repr() 方法使用字符串原意(方便机器阅读,而不是方便人阅读)
1 | line = 'Hello Tom ! \n Hi' |
连接
字符串可以由 + 操作符连接(粘到一起),可以由 * 表示重复
1 | # 3 times 'un', followed by 'ium' |
相邻的两个字符串文本自动连接在一起
1 | 'Py' 'thon' |
这种方法只用于字面意义上的两个字符串文本,不能用于 变量 和 字符串表达式:
1 | prefix = 'Py' |
使用 + 将多个变量连成字符串,或将一个变量和一个字符串文本连接成字符串
1 | prefix + 'thon' |
使用 , 连接成元组
1 | prefix='Py'; suffix='thon' |
用 % 连接一个字符串和一组变量,字符串中的特殊标记会被自动用右边变量组中的变量替换,功能比较强大,借鉴了 C 语言中 printf 函数的功能:
1 | a='Tom' |
较长字符串的表示方法
如果需要写一个长字符串,跨越了2行或更多行,则可以使用三种方法:
使用三引号,行尾换行符会被自动包含到字符串中,但是可以在行尾加上 \ 来避免这个行为。下面的示例: 可以使用反斜杠作为行结尾的连续字符串,它表示下一行在逻辑上是本行的后续内容:
1 | print("""\ |
由 + 操作符连接:
1 | t = "This is not the best way to join two long strings " + \ |
使用圆括号构成一个单独的表达式,如果不使用圆括号,就只有第一个字符串对变量进行赋值,第二个字符串则会导致 IndentationError 异常。建议总是使用圆括号将跨越多行的任何语句进行封装而不使用转义的换行符。
1 | s = ("This is the nice way to join two long strings " |
操作符
由于字符串是固定序列,所有可用于固定序列的功能都可用于字符串,包括使用 in 进行成员关系测试,使用 += 进行追加操作,使用 * 进行复制,使用 *= 进行增强的赋值复制等。
* 操作符提供了字符串复制功能:
1 | s='#' |
在用于字符串时,如果成员关系操作符 in 左边的字符串是右边字符串的一部分或者相等,就返回 True
1 | 'usr' in '/usr/local/bin' |
字符串支持通常的比较操作符 < 、<= 、= 、!= 、> 与 >= ,这些操作符在内存中逐个字节对字符串进行比较
作为一种策略(以便防止出错),Python 并不进行推测字符串是哪个国家的语言字符。在字符串比较时,Python 使用的是字符串的内存字节的形式,此时的排序是基于 Unicode 编码格式的,比如对英语就是按 ASCII 顺序。对要比较的字符串进行小写或大写,会产生更贴近自然英语的排序。
字符串的切片与步距
字符串也可以被截取(检索)。字符串的索引位置从0开始,直至字符串长度值减去1。索引用于获得单个字符,切片则可以获得一个子字符串
单个字符的提取
Python 没有单独的字符类型;一个字符就是一个简单的长度为 1 的字符串。
1 | word = 'Python' |
使用负索引位置也是可以的一一此时的计数方式是从最后一个字符到第一个字符。
1 | word[-1] # last character |
注意: -0 实际上就是 0,所以它不会导致从右边开始计算。-1 这个值总是代表字符串的最后一个字符。 存取超过范围的索引位置(或空字符串中的索引位置)会产生 IndexError 异常。
分片操作
下面提到的 seq 可以是任意序列,比如列表、字符串或元组。start 、end 与 step 必须都是整数(或存放整数的变量)。
分片操作符 [] 有三种语法格式:
语法格式一:seq [start] :从序列中提取从start开始的数据项:
1 | s = "The waxwork man" |
语法格式二:seq[start:end],一个冒号,从(包含) start 开始的数据项到(不包含) end 结束的数据项提取一个分片。如果使用这种语法格式就可以省略任意的整数索引值。
如果省略了起点索引值,就默认为0;
如果省略了终点索引值,就默认为
len(seq),即要切片的字符串的长度;如果省略了两个索引值,比如
s[:]则与s[0:len(s)]是一样的,作用都是提取也就是复制整个序列
给定赋值操作 s = "The waxwork man",图2-2展示了字符串s的一些实例分片
1 | s = "The waxwork man" |
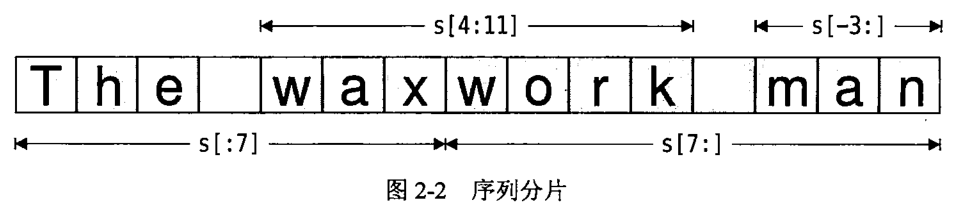
实际上由于文本 wo 在原始字符串中,因此我们也可以写成 s[:12] + s[7:9] + s[12:] 达到同样的效果。在涉及很多字符串时,使用 + 进行连接、使用 += 进行追加等操作并不是特别高效,如果需要连接大量的字符串,通常最好使用 str.join() 方法。
语法格式三:seq[start:end:step],两个冒号,与上面用法类似,区别在于不是提取每一个字符,每隔 step 个字符进行提取;也可以省略两个索引
如果省略了起点索引值,就默认为0 ——除非给定的是负的step值,此时起点索引值默认为-1
如果省略了终点索引值,那么默认为
len(seq)——除非给定的是负的step值, 此时终点索引值默认为字符串起点前面不能忽略
step,并且step不能为 0。如果不需要step,那么应该使用不包含step的第二种语法(一个冒号)
给定赋值操作 s = "he ate camel food" 下图展示了字符串带步距的分片的两个实例:
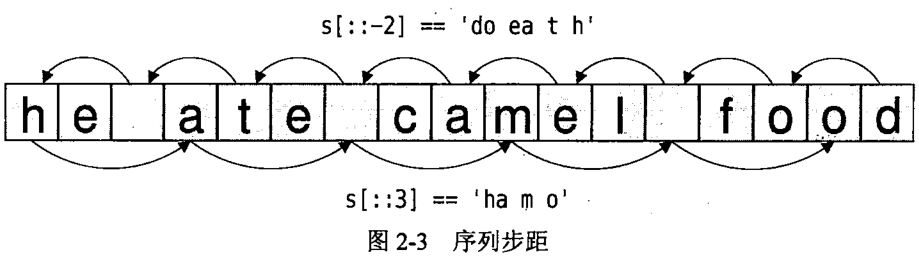
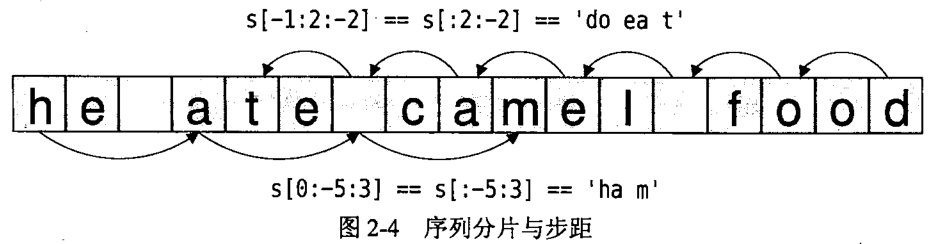
更常见的情况下,步距是与字符串之外的序列类型一起使用的,但是也存在用于字符串的情况:
1 | s, s[::-1] |
step 为 -1 意味着每个字符都将被提取,方向为从终点到起点,因此会产生反转的字符串。
注意: 包含起始的字符,不包含末尾的字符,这使得 s[:i] + s[i:] 永远等于 s:
1 | word = 'Python' |
常用方法
大小写转换
s.title():返回字符串s的副本并将每个单词的首字母变为大写,其他字母变为小写
1 | s='hello world' |
s.capitalize():返回字符串s的副本并将首字母变为大写
1 | s='jerry' |
s.lower():将字符串转为小写
1 | s='Jerry' |
s.upper():将字符串转为大写
1 | s='hwaddr=00:0c:29:85:60:ee' |
s.swapcase():交换大小写,返回s的副本并将其中大写字符变为小写,小写字符变为大写
1 | s='hwaddr=00:0C:29:85:60:EE' |
剔除字符串
s.strip(chars):返回s的副本,并将两边(开头和结尾)的空白字符(或字符串为 chars 的字符)移除。
s.lstrip(chars):返回s的副本,并将左边(开头)的空白字符(或字符串为 chars 的字符)移除。
s.rstrip(chars):返回s的副本,并将右边(结尾)的空白字符(或字符串为 chars 的字符)移除。
1 | s=" \n\nMy name is Linux. \n I'm 18 years old.\n\n " |
填充字符串
s.center(width,char):返回一个长度为 width 的字符串,并且s在这个字符串中处于 居中 位置,不足部分使用空格或可选的 char (长度为1的字符串)进行填充。
s.ljust(width,char): 返回一个长度为 width 的字符串,并且s在这个字符串中处于 左 对齐位置,不足部分使用空格或可选的 char (长度为1的字符串)进行填充。
s.rjust(width,char): 返回一个长度为 width 的字符串,并且s在这个字符串中处于右 对齐位置,不足部分使用空格或可选的 char (长度为1的字符串)进行填充。
1 | s='Shopping list' |
s.zfill(w):返回s的副本,如果 s 的长度比 w 短,就在开头使用 0 填充,使其长度为 w ,其中 w 必须为整数:
1 | s='10' |
统计字符串次数
s.count(t,start,end):返回字符串 s 中(或在 s 的 start:end 切片中)字符串 t 出现的次数
1 | s="You're so You're so... sexy sexy sexy I need your love" |
匹配开头和结尾
s.startswith(x,start,end):如果 s (或 s 的 start:end 分片)以字符串 x (或以元组 x 中的任意字符串)开始,就返回 True ,否则返回 False。
s.endswith(x,start,end):如果 s (或 s 的 start:end 分片)以字符串 x (或以元组 x 中的任意字符串)结尾,就返回 True ,否则返回 False。
1 | s='jerry and tom' |
分隔
s.split(t,n):以 t 作为分隔符,分隔 n 次,并返回结果。如果 t 未指定则默认以空白符作为分隔,如果 n 未指定则尽可能多地分隔。使用 s.rsplit(t,n) 可以从右往左进行分割——只有在指定了 n 并且 n 小于可能分割的最大次数是才能起作用。
1 | s='/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin' |
s.partition(t):返回包含3个字符串的元组,字符串 s 中 从左往右 第一个 t 的左边的部分,t , 从左往右 第一个 t 右边的部分。如果 t 不在 s 内则返回 s 与两个空字符串。
s.rpartition(t) :返回包含3个字符串的元组,字符串 s 中 从右往左 第一个 t 的左边的部分,t , 从右往左 第一个 t 右边的部分。如果 t 不在 s 内则返回 s 与两个空字符串。
1 | s='/usr/local/bin/firefox' |
位置检索
s.index(t,start,end):如果在 s (或 s 的 start:end 分片 )中 从左往右 能找到字符串 t ,则返回 最左边 的 t 的位置;如果没有找到则产生 ValueError 异常;
s.rindex(t,start,end):如果在 s (或 s 的 start:end 分片 )中 从右往左 能找到字符串 t ,则返回 最右边 的 t 的位置;如果没有找到则产生 ValueError 异常;
s.find(t,start,end):如果在 s (或 s 的 start:end 分片 )中 从左往右 能找到字符串 t ,则返回 最左边 的t的位置;如果没有找到则返回 -1;
s.rfind(t,start,end):如果在 s (或 s 的 start:end 分片 )中 从右往左 能找到字符串 t ,则返回 最右边 的 t 的位置;如果没有找到则返回 -1;
1 | s='/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin' |
替换
s.replace(t,u,n):返回 s 的副本,其中每个(或最多 n 个,若指定了n)字符串 t 使用 u 进行替换。
1 | s="You're so You're so... sex sex sex I need your love" |
可迭代数据类型转为字符串
x.join(seq):以 x (可以为空)作为连接符,将可迭代对象 seq 中的每个元素连接起来。
1 | s=['usr','local','bin'] |
x.join() 方法也可以与内置的 reversed() 函数一起使用,以实现对字符串的反转,例如 "".join(reversed(s))。当然通过步距也可以更精确地获取同样的结果,比如 s[::-1] 。
1 | s=['1', '2', '3', '4', '5'] |
其他
s.isidentifier():如果 s 非空,并且是一个有效的标识符(变量名),则返回 True。
s.isalnum():如果 s 非空,并且其中每一个字符都是字母或数字,则返回 True。
s.isdigit():如果 s 非空,并且其中每一个字符都是一个 ASCII 数字,则返回 True。
1 | s='/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin' |
连接效率测试与总结
实验比较 + 和 x.join(s) 的连接效率
1 | #!/usr/bin/env python |
运行结果
1 | [user1@CentOS-7.3 tmp]$ ./test.py |
总结:
使用
+连接效率低是在连续进行多个字符串连接的时候出现的,如果连接的个数较少,加号连接效率反而比join连接效率高。join使用略复杂,但对多个字符进行连接时效率高,只会有一次内存的申请。而且如果是对list的字符进行连接的时候,这种方法必须是首选。使用
+进行字符串连接,操作效率低下,因为 Python 中字符串是不可变的类型,使用+连接两个字符串时会生成一个新的字符串,生成新的字符串就需要重新申请内存,当连续相加的字符串很多时效率低下就很显然了。

