在平常运维工作中,难免会有一些修改服务配置文件的操作,为了安全和可以回滚起见,我们习惯性的会将源配置文件做一个拷贝,这样以来即便配置文件参数被修改错了也没事,可以快速从备份的副本还原回来。
同样,在 Python 中如果涉及到数据传递,在传递过程中就有可能会发生数据被修改的问题,为了防止数据被修改,就需要生成一个副本,这就产生了拷贝。
基本概念
对象
在 Python 中,一切皆对象。任何数据类型、函数、模块在 Python 中都被当做对象处理。所有的 Python 对象都有三个属性:身份、类型、值。
1 | name = 'Tom' # 建立一个对象引用 |
可变对象与不可变对象
可变对象:对象的值可变,身份是不变的,例如列表、字典、集合,这些都是容器类型的数据,容器的内存地址是不变的,发生变化的是容器内部的数据。
不可变对象: 对象的值和身份都是不变的,新创建的对象被原来的变量名引用,旧的对象就会被丢弃,最后交给垃圾回收机制处理掉,例如数字、字符串、元组。
变量赋值
或许在很多人的直观印象中,变量是一个容器,给变量赋值,就像是往一个存储的容器中填入一个数据,再次赋值就是把容器中的数据换掉,在 Python 中,这种理解是不准确的!
更恰当的比喻是,我们可以把变量当做是一个标签:给变量赋值就是把标签贴在一个物体上;再次赋值就是把标签取下来贴在另一个物体上。
对象引用
在 Python 程序中,每个对象都会在内存中申请开辟一块空间来保存该对象,该对象在内存中所在位置的地址被称为引用。在开发程序时,所定义的变量名实际就是对象的地址引用。
引用实际就是内存中的一个数字地址编号(内存地址),在使用对象时,只要知道这个对象的内存地址,就可以操作这个对象,但是因为内存地址不方便在开发时使用和记忆,所以使用变量名的形式来代替对象的内存地址。 在 Python 中,变量就是地址的一种表示形式,并不开辟存储空间。
就像在访问网站时我们输入的是域名,而不是 IP ,但实际都是通过 IP 地址来进行网络通信的,而 IP 地址不方便记忆,所以使用域名来代替 IP 地址,在使用域名访问网站时,域名被 DNS 服务器解析成 IP 地址来使用。
在创建一个数据项时,将其赋值给一个变量,或者将其插入到一个组合中时,实际上是使得某个变量对内存中存放数据的对象进行引用,使用 del 时,实际上是删除了相应的对象引用。
不可变对象的引用赋值
1 | a = 1 |
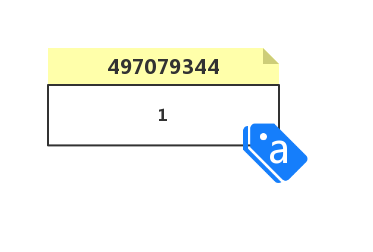
a = 1 相当于把标签 a 贴在了 1 上,他的身份(内存地址)是 497079344 :
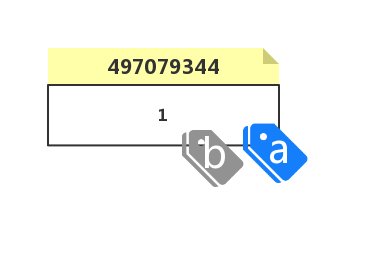
使用 b = a 的方式,实际上就相当于把标签 b 也贴在了标签 a 贴的那个物体上,也就是 a 和 b 都指向了同一块内存地址,可以简单的认为给对象的引用做了一个别名:
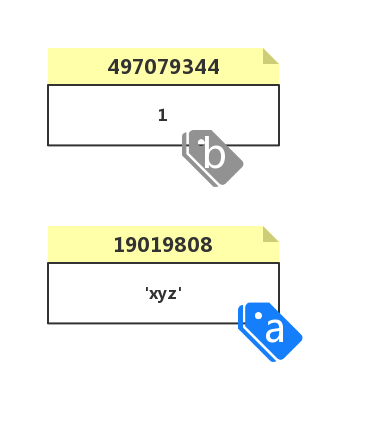
当重新为 a 进行赋值时(a='xyz'),实际上是在内存中新开辟了一段空间存放字符串对象 'xyz' 并把 a 的指向改为 'xyz',而 b 则还是原来的对象引用:
可变对象的引用赋值
可变对象保存的其实是对象引用(内存地址),而不是真正的对象数据。当对可变对象进行赋值时,只是将可变对象中保存的引用指向了新的对象。
1 | a = [1, 2, 3] |
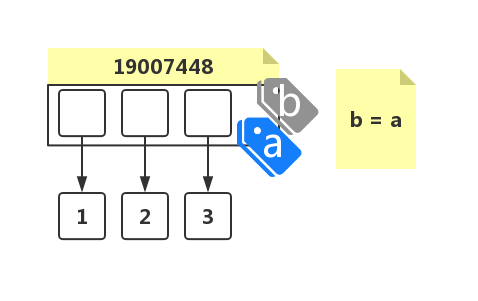
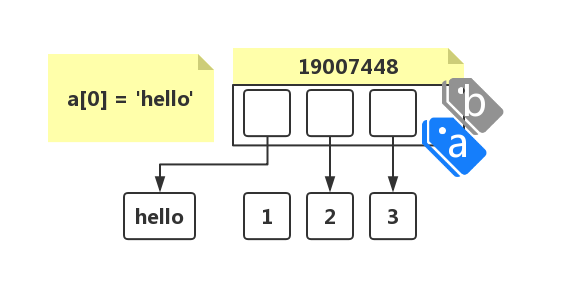
上例中变量 a 并不是引用了实际数据 1, 2, 3 的内存地址,而是单纯的列表的内存地址,引用实际数据的是这个列表对象而不是变量 a:
当改变列表中的数据时,改变的不是列表的内存地址,而改变的是列表中对实际数据的引用:
浅拷贝
不可变对象的拷贝
1 | import copy |
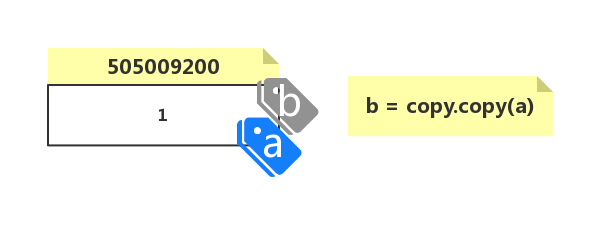
不可变对象的拷贝就是对象赋值,实际上是让多个对象同时指向一个引用 (内存地址):
可变对象的拷贝
1 | import copy |
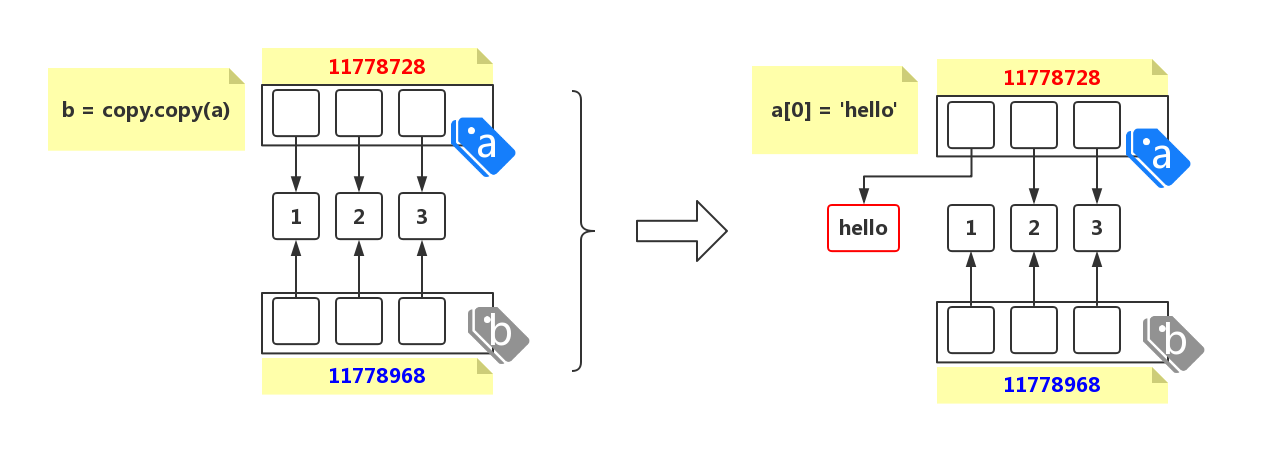
可变对象的拷贝,会在内存中开辟一个新的空间来保存拷贝的数据。当再改变之前的对象时,对拷贝之后的对象没有任何影响:
可变对象与不可变对象的组合
1 | import copy |
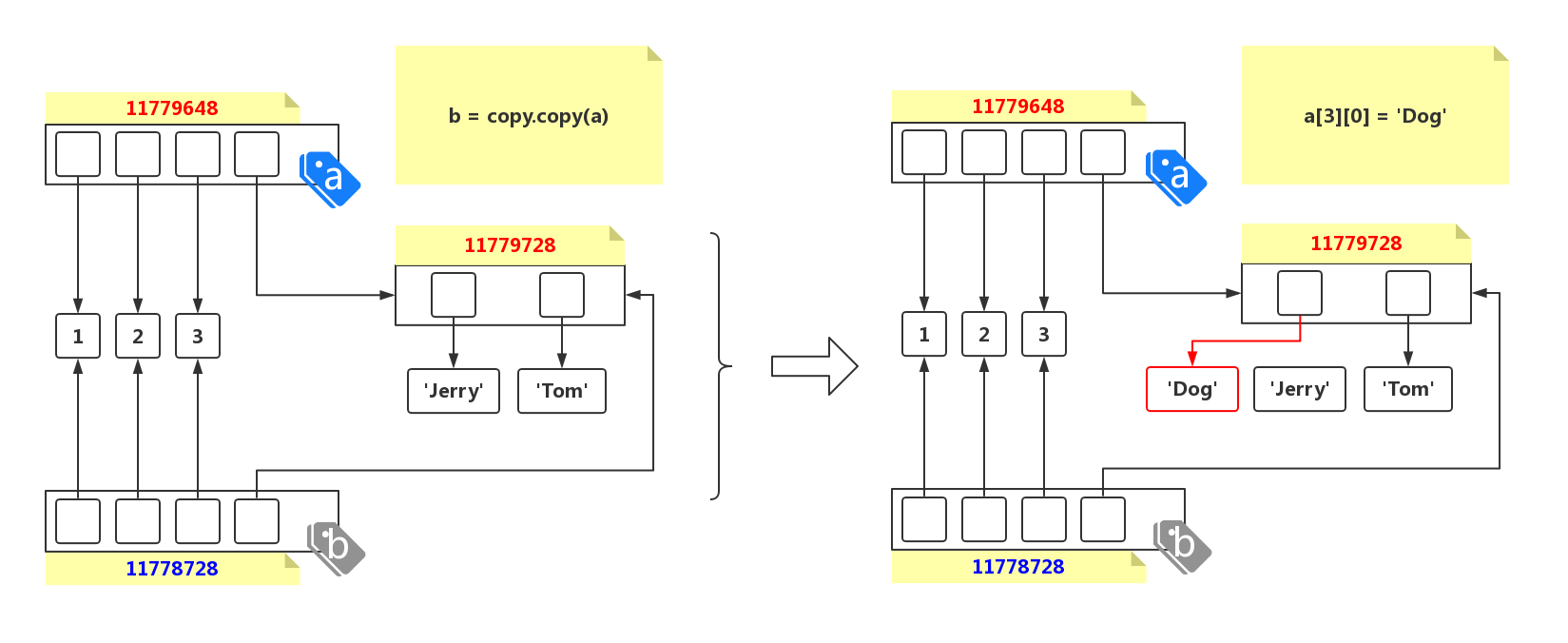
复杂对象在拷贝时并没有解决数据在传递之后数据改变的问题。 这是因为 copy() 函数在拷贝对象时,只是将指定对象中的所有引用拷贝了一份,如果这些引用当中包含了一个可变对象的话,那么数据还是会被改变。 这种拷贝方式,称为浅拷贝。
浅拷贝只拷贝顶层数据,不拷贝子层数据:
再比如
1 | d1=dict.fromkeys(['host1','host2','host3'],['test1','test2']) |
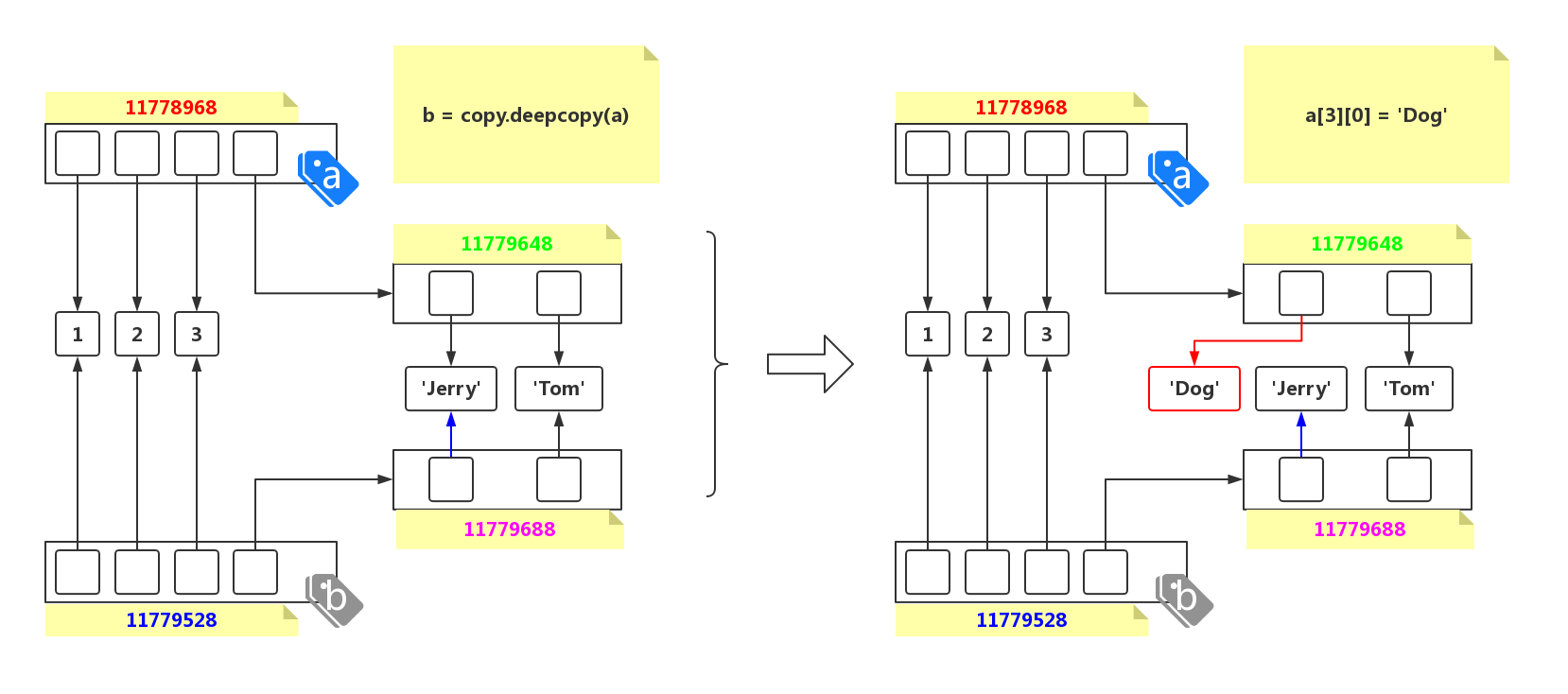
深拷贝
1 | import copy |
深拷贝会逐层进行拷贝,直到拷贝的所有引用都是不可变引用为止:
总结
在 Python 中,默认的拷贝方式是浅拷贝。从时间上看,浅拷贝花费时间更少;从使用空间上看,浅拷贝花费内存更少;从执行效率上看,浅拷贝只拷贝顶层数据,一般情况下比深拷贝效率高。
不可变对象在赋值时会开辟新空间。
深、浅拷贝对不可变对象拷贝时,不开辟新空间,相当于赋值操作。
浅拷贝在拷贝时,只拷贝第一层中的引用,如果元素是可变对象,并且被修改,那么拷贝的对象也会发生变化。
大多数情况下,编写程序时,都是使用浅拷贝,除非有特定的需求。

