基本要点
函数即对象
函数名的本质就是一个变量,保存了函数所在的内存地址。
1 | #!/usr/bin/env python3 |
函数对象可以被赋值给变量。
1 | #!/usr/bin/env python3 |
函数名可以作为另外一个函数的参数。
1 | #!/usr/bin/env python3 |
函数名可以作为另外一个函数的返回值。
1 | #!/usr/bin/env python3 |
函数名可以作为容器类型(例如列表、元组,字典)的元素。
1 | #!/usr/bin/env python3 |
函数嵌套
函数都有各自的作用域:
1 | def foo(): |
Python 允许创建嵌套函数,通过在函数内部 def 的关键字再声明一个函数即为嵌套:
1 | def outer(): |
闭包
认识闭包
在一些语言中,在函数中可以(嵌套)定义另一个函数时,如果内部的函数引用了外部的函数的变量,则可能产生闭包。运行时,一旦外部的函数被执行,一个闭包就形成了,闭包中包含了内部函数的代码,以及所需外部函数中的变量的引用。闭包可以用来在一个函数与一组“私有”变量之间创建关联关系。在给定函数被多次调用的过程中,这些私有变量能够保持其持久性。 —— 维基百科
闭包(closure)是函数式编程的重要的语法结构,在 Python 的嵌套函数中,如果内部函数中对在外部作用域(但不是在全局作用域)的变量进行了引用,并且这个内部函数名被当成对象返回,这就形成了一个闭包(closure)。
1 | def echo_info(name): # name 是外层函数的变量 |
在上述的例子中 echo 就是内部函数,并且在 echo 中引用了外部作用域的变量 name ,而变量 name 是在外部作用域 echo_info 里面的,并且不是全局的作用域,函数名 echo 又作为了外层函数的返回值,此时内部函数 echo 就形成了一个闭包 。
闭包 = 函数块 + 定义函数时的环境,echo 就是函数块, name 就是环境,当然这个环境可以有很多,不止一个简单的 name 。
闭包的用途
闭包的最大用处有两个:
内部函数可以引用外部作用域的变量。
让外部作用域的变量的值始终保持在内存中。
闭包存在有什么意义呢?为什么需要闭包?我们来看爬取网页源码的例子:
普通方式爬取
1 | from urllib.request import urlopen |
闭包的方式爬取
1 |
|
假设我们要对函数调用 100 次,第二种爬取方式要比第一种更节省资源。因为第一种每调用一次函数,就会在内存中创建一次对象引用 url = 'https://movie.douban.com',调用 100 次就创建了一百次对象引用。而第二种是个闭包函数,对象引用 url = 'https://movie.douban.com' 会一直在内存中存在,而不会被创建一百次。
原因就在于 geturl 是 inner_geturl 的父函数,而 inner_geturl 被传入了一个父级函数的变量 url,这导致 inner_geturl 始终在内存中,而 inner_geturl 的存在依赖于 geturl,因此 geturl 也始终在内存中,不会在调用结束后被垃圾回收机制回收。
如何判断是不是闭包
闭包函数相对与普通函数会多出一个 __closure__ 的属性,里面定义了一个元组用于存放所有的 cell 对象,每个 cell 对象保存了这个闭包中所有的外部变量。使用它就可以判断函数是否形成了闭包。例如:
1 | def mkinfo(name, age, sex='F'): |
输出结果如下:
1 | (<cell at 0x7f099fdf67c8: int object at 0x7f099fcc5680>, <cell at 0x7f099fdf67f8: str object at 0x7f099fdbc180>, <cell at 0x7f099fdf6828: str object at 0x7f099fdddce0>) |
装饰器
装饰器前戏
假设有如下函数,被其他各种程序调用:
1 | #!/usr/bin/env python3 |
现在公司要进行绩效考核,考核标准为 Python 代码中每个函数所执行的时间。如果在每个函数中加入时间统计的功能,则会造成大量雷同的代码,为了解决这个问题,我们想到可以重新定义一个函数用来专门计算时间:
1 | #!/usr/bin/env python3 |
但是这样的话,基础平台的函数修改了名字,很容易被业务线的人投诉的,因为我们每次都要将一个函数作为参数传递给 spent_time 函数。而且这种方式已经破坏了原有的代码逻辑结构,之前执行业务逻辑时运行 dns_resolver() 、 os_release(),但是现在不得不改成 spent_time(dns_resolver)、spent_time(os_release) ,这在生产环境是很不切合实际的,使用装饰器就可以很好地解决这个问题。
在此之前,我们先认识一下 开放封闭原则。
开放封闭原则
软件开发中的 “开放-封闭” 原则 :
封闭:已实现需求的功能代码块不应该再被修改。
开放:对现有功能的扩展开放。
装饰器
装饰器(Decorator)本质上是一个返回函数对象的高阶函数,该函数用不需要修改源函数代码(函数体、调用方式、返回值)的前提下为其增加额外的功能,装饰器的返回值也是一个函数对象。
概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能 ,它常用于有切面需求的场景,比如插入日志、性能测试、事务处理、缓存、权限校验等应用场景。
现在回到上面绩效的例子,假设我们已经在源代码的基础上单独添加了计算时间的函数:
1 | #!/usr/bin/env python3 |
在上面的代码中,函数 spent_time 就是一个装饰器, funcname 就是被装饰的对象。看起来像 dns_resolver 、os_release 被上下时间函数装饰了,并且没有改变原函数的调用方式,但是每次调用时都必须进行一次赋值操作。为了避免这种重复性赋值操作,Python 使用了 @ 语法糖:
1 | #!/usr/bin/env python3 |
如上所示,装饰器直接省去赋值操作,这样就提高了程序的可重复利用性,并增加了程序的可读性。并且 dns_resolver = spent_time(dns_resolver) 实际上是把 inner 的对象引用给了 dns_resolver ,而 inner 中的变量 funcname 之所以可以用,是因为 inner 是一个闭包函数,它引用了外部作用域 spent_time 接收到的 funcname 。
带参数的装饰器
上面我们已经用装饰器解决了调用方式和重复赋值的问题。现在问题又来了,这个月的绩效考核完了,函数代码不需要统计花费时间了,下个月又要再次进行一次考核。
解决这个问题最笨的办法就是,如果不考核了我们把装饰器的使用给注释掉,如果开始考核再把注释取消。如果有一千个函数的话,就要每次都要操作一千次。虽然编辑器都有批量查找替换的功能,但是这种方法很显然并不符合实际。
那么,有没有更简单的办法呢?我们可以使用一个全局变量作为 flag,再配合使用可以传入参数的装饰器即可:
1 | #!/usr/bin/env python3 |
上面的代码开发完之后,如果想用装饰器就将全局变量 flag 的值改为 True,不想用就改为 False,这样以来就使用带参数的装饰器灵活地解决是否启用装饰的问题。
对象属性复制
函数对象都有 __name__ 等属性,在上面的例子中,看似已经把所有问题都解决掉了,但是当我们打印经过装饰器做了装饰之后的原函数,它们的 __name__ 已经发生了变化:
1 | print("function dns_resolver's name :", dns_resolver.__name__) |
结果如下:
1 | function dns_resolver's name : inner |
本来 dns_resolver 在没有被装饰的时候,dns_resolver.__name__ 就是 dns_resolver,而装饰后却变成了 inner ,因为返回的那个 inner() 函数名字就是 inner,所以需要把原始函数的 __name__ 等属性复制到 inner() 函数中,否则有些依赖函数签名的代码执行就会出错。
不需要编写 inner.__name__ = func.__name__ 这样的代码,Python 内置的 functools.wraps 就是干这个事的,所以一个完整的 decorator 的写法如下:
1 | #!/usr/bin/env python3 |
如果是带参数的 decorator,应该这样写:
1 | #!/usr/bin/env python3 |
其中 from functools import wraps 是导入 functools 模块的 wraps 功能,现在只需要记住在定义 inner() 的前面加上 @wraps(funcname) 即可。由此一来,属性也完成了复制:
1 | function dns_resolver's name : dns_resolver |
多层装饰器
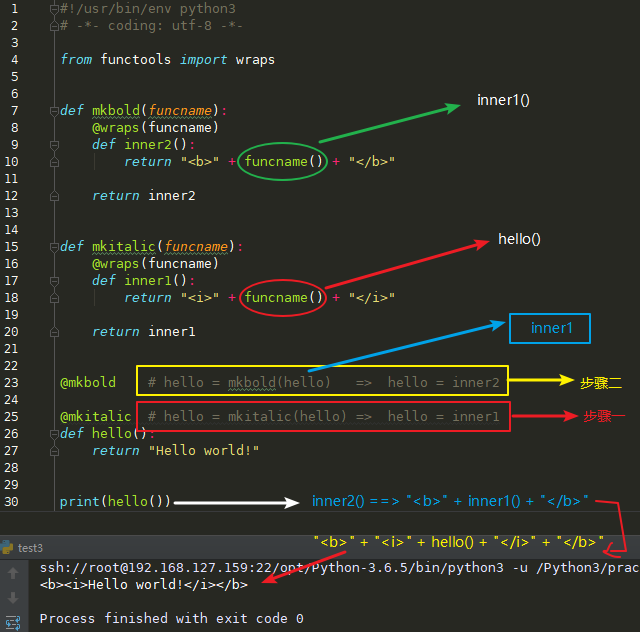
多层装饰器有点类似于俄罗斯套娃,我们来看下面的代码:
1 | #!/usr/bin/env python3 |
多层装饰器在执行时,最先执行的是离原函数最近的一层装饰器,依次往外执行,下面用一张图理解一下上述代码中装饰器的执行过程: