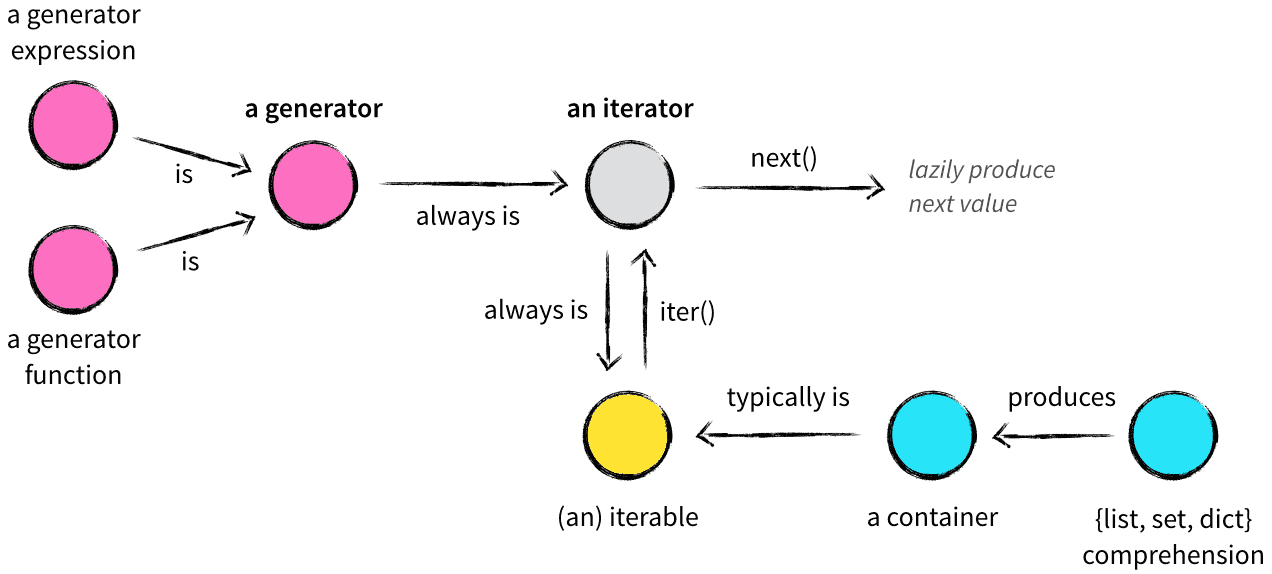
在了解 Python 的数据结构时,容器(container)、可迭代对象(iterable)、迭代器(iterator)、生成器(generator)、列表/集合/字典推导式(list,set,dict comprehension)众多概念参杂在一起,难免让初学者一头雾水,我将用一篇文章试图将这些概念以及它们之间的关系捋清楚 。
容器(container)
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用 in , not in 关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特例并不是所有的元素都放在内存)。在 Python 中,常见的容器对象有:
- list, deque, ….
- set, frozensets, ….
- dict, defaultdict, OrderedDict, Counter, ….
- tuple, namedtuple, …
- str
容器比较容易理解,我们可以把它看作是一个盒子、一栋房子、一个柜子,里面可以装任何东西。从技术角度来说,当它可以用来询问某个元素是否包含在其中时,那么这个对象就可以认为是一个容器。
可迭代对象(iterable)
很多容器都是 Iterable 对象,此外还有更多的对象同样也是 Iterable 对象,比如处于打开状态的 files,sockets 等等。但凡是可以返回一个 迭代器 的对象都可称之为 Iterable 对象。Iterable 对象和容器一样是一种通俗的叫法,并不是指某种具体的数据类型。
我们可以使用 isinstance() 判断一个对象是否是 Iterable 对象:
1 | from collections import Iterable |
迭代器内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。迭代器有一种具体的迭代器类型,比如 list_iterator,set_iterator。
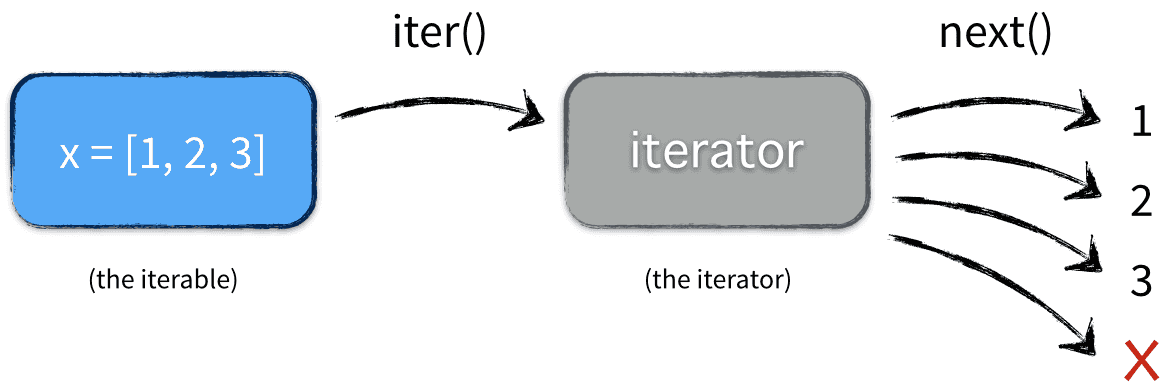
可迭代对象都有 x.__iter__ 和 iter(x) 方法,这两个方法本质一样,都会返回一个迭代器。能直接作用于 for 循环的对象统称为可迭代对象,要想可迭代,内部必须有一个 __iter__ 方法。
1 | x = [1, 2, 3] |
上例中 y 和 z 是两个独立的迭代器 ( iterator)。
for循环的本质
当你在写:
1 | x = [1, 2, 3] |
实际上 for 循环本质上做了三件事:
- 调用
iter()方法将可迭代的对象转为迭代器,即:iter(x) - 不断地调用
next()方法,返回迭代器中下一个元素的值 - 处理 StopIteration 异常
因此上述例子完全等价于:
1 | # 首先获得迭代器对象: |
迭代器(iterator)
迭代器(iterator)是一个带状态的对象,同时满足下列两个条件的对象都是迭代器:
条件1:有 __iter__() 方法:等同于 iter() ,如果对象本身就是迭代器对象,则返回迭代器自身。
1 | L = [1,2,3,4] |
条件2:有 __next__() 方法:等同于 next() ,返回容器中的下一个值,如果容器中没有更多元素了,则抛出 StopIteration 异常。
1 | L = [1, 2, 3, 4] |
在迭代器中每次调用 next() 方法的时候做两件事:
- 为下一次调用
next()方法修改状态 - 为当前这次调用生成返回结果
迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。
我们都知道 range() 可以被 for 循环,也就是说它是一个可迭代对象,那么 range() 是不是一个迭代器呢?
1 | print('__iter__' in dir(range(12))) |
因为 range() 没有 __next__ 方法,所以它只是可迭代对象而不是迭代器。另外,还可以使用 isinstance() 判断一个对象是否是 Iterator 对象。
1 | from collections import Iterator |
生成器(generator)
通过列表生成式,可以直接创建一个列表。但是受到内存限制,列表容量肯定是有限的。而且创建一个包含 100 万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的 list,从而节省大量的空间。在 Python 中这种一边循环一边计算的机制,称为生成器(generator)。
生成器表达式(generator expression)
创建生成器的第一种方法很简单,只要把一个列表生成式的 [] 改成 (),就创建了一个 generator,生成器表达式是列表生成式的生成器版本,看起来像列表生成式,但是它返回的是一个生成器对象而不是列表对象:
1 | L = [x * x for x in range(5)] |
创建 L 和 g 的区别仅在于最外层的 [] 和 (),L 是一个 list 对象,而 g 是一个 generator 对象,我们可以直接打印出 list 的每一个元素,但怎么打印出 generator 的每一个元素呢?
上述例子中,列表生成式相当于做好的 5 盘菜,什么时候想吃就什么时候吃,数据都都在内存空间,什么时候想调用就调用,但是比较占空间;而生成器相当于一位厨师,现在什么菜都没有,当你想吃第一道菜的时候就可以叫厨师做出来,以此类推。如果不吃,数据永远不会生成,不占内存空间,但是算法决定了必须从第一盘菜开始吃,只有在前 9 盘菜吃完才能吃最后一盘,所以如果要打印出 generator 的每一个元素,可以通过 next() 函数不断地获得 generator 的下一个返回值:
1 | next(g) |
generator 保存的是算法,每次调用 next(g),就计算出 g 的下一个元素的值,直到计算到最后一个元素,没有更多的元素时抛出 StopIteration 的错误。当然上面这种不断调用 next(g) 实在是太变态了,正确的方法是使用 for 循环,因为 generator 也是可迭代对象:
1 | g = (x * x for x in range(5)) |
所以当我们创建了一个 generator 后基本上永远不会调用 next(),而是通过 for 循环来迭代它,并且不需要关心 StopIteration 的错误。
generator 非常强大。如果推算的算法比较复杂,用生成器表达式的 for 循环无法实现的时候,还可以用函数来实现。 比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1 | 1, 1, 2, 3, 5, 8, 13, 21, 34, ... |
斐波拉契数列用列表生成式写不出来,但是用函数把它打印出来却很容易:
1 | #!/usr/bin/env python3 |
注意,赋值语句: prev, curr = curr, curr + prev 相当于:
1 | t = (curr, curr + prev) # t 是一个tuple |
但不必显式写出临时变量 t 就可以完成赋值 。
yield 关键字
生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面一样写 iter() 和 next() 方法了,只需要一个 yiled 关键字。 生成器一定是迭代器(反之不成立),因此任何生成器也是以一种懒加载的模式生成值。
仔细观察,可以看出 fib 函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似 generator。 也就是说上面的函数和 generator 仅差一步之遥。要把 fib 函数变成 generator,只需要把 print(curr) 改为 yield curr 就可以了:
1 | #!/usr/bin/env python3 |
这就是定义 generator 的另一种方法。如果一个函数定义中包含 yield 关键字,那么这个函数就不再是一个普通函数,而是一个 generator 。上述代码执行的结果为:
1 | <generator object fib at 0x00C4F7B0> |
当执行 f=fib(5) 返回的是一个生成器对象,此时函数体中的代码并不会执行,只有显示或隐示地调用 next() 的时候才会真正执行里面的代码。将 print(f) 改为 print(list(f)) 后,list() 方法就会隐式地调用 next() ,并得到我们所期望的结果:
1 | [1, 1, 2, 3, 5] |
把函数改成 generator 后,我们基本上从来不会用 next()来获取下一个返回值,而是直接使用 for 循环来迭代:
1 | for n in fib(5): |
generator 和函数的执行流程不一样。函数是顺序执行,遇到 return 语句或者最后一行函数语句就返回。而变成 generator 的函数,在每次调用 next() 的时候才执行,遇到 yield 语句才返回,再次执行时从上次返回的 yield 语句处继续执行。
举个简单的例子,定义一个 generator,依次返回数字 1,3,5:
1 | def odd(): |
调用该 generator 时,首先要生成一个 generator 对象,然后用 next() 函数不断获得下一个返回值:
1 | o = odd() |
可以看到 odd 不是普通函数,而是 generator 。在代码执行过程中只要遇到 yield 就中断,下次又继续执行。执行 3 次 yield 后,已经没有 yield 可以执行了,所以第 4 次调用 next(o) 就报错。
return
生成器函数跟普通函数只有一点不一样,就是把 return 换成 yield,其中 yield 是一个语法糖,内部实现了迭代器协议,同时保持状态可以挂起。
在一个生成器中,如果没有 return,则默认执行到函数完毕;如果在执行过程中遇到 return,则直接抛出 StopIteration 终止迭代。
1 | #!/usr/bin/env python3 |
执行的结果如下:
1 | 5 |
遇到 return 就意味着迭代结束,for 循环不报错的原因是我们之前说过的,内部处理了迭代结束的这种情况。
1 | #!/usr/bin/env python3 |
生成器在 Python 中是一个非常强大的编程结构,可以用更少地使用中间变量写流式代码,此外,相比其它容器对象它更能节省内存和 CPU,当然它可以用更少的代码来实现相似的功能。现在就可以动手重构你的代码了,但凡看到类似:
1 | def something(): |
都可以用生成器函数来替换:
1 | def something(): |
如果直接对文件对象调用 read() 和 readlines() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。通过 yield,我们不再需要编写读文件的迭代类就可以轻松实现文件读取:
1 | def read_file(fpath): |
更加便利的方法是使用 for 循环直接对文件对象进行迭代:
1 | with open('test.log','r',encoding='utf-8') as frd: |
send
生成器有个 send() 方法,用于传入值给生成器
1 | #!/usr/bin/env python3 |
可以通过断点来观察执行流程:
- 打印 ok => yield 7
- 当再 next 进来时,将 None 赋值给 s并打印
- 然后返回 8
练习
使用文件读取,找出文件中最长的行
1 | #!/usr/bin/env python3 |
生成器面试题
请写出下面代码的执行结果:
1 | def add(n, i): |
执行结果为:
1 | [20, 21, 22, 23] |
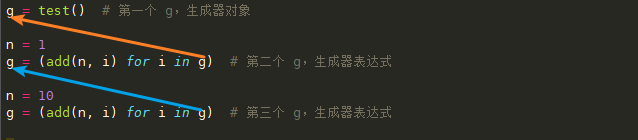
在上述代码中
1 | g = test() |
可以写成
1 | g = test() # 第一个 g,生成器对象 |
再进行推算
也就是
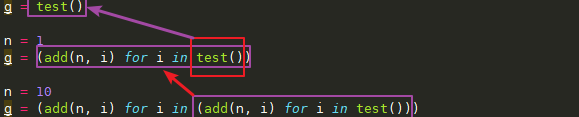
生成器在被取值之前不会进行运算,等最后交给 list() ,这时候就需要从生成器对象中取值,此时 n 的值是 10,计算完成后便是:
1 | [20, 21, 22, 23] |
总结
- 容器是一系列元素的集合,str、list、set、dict、file、sockets 对象都可以看作是容器,容器都可以被迭代(用在 for,while 等语句中),因此他们被称为可迭代对象。
- 可迭代对象实现了
iter()方法,该方法返回一个迭代器对象。 - 迭代器持有一个内部状态的字段,用于记录下次迭代返回值,它实现了
__next__()和__iter__()方法,迭代器不会一次性把所有元素加载到内存,而是需要的时候才生成返回结果。 - 生成器是一种特殊的迭代器,它的返回值不是通过
return而是用yield。
参考链接:

