什么是序列化
在程序运行的过程中,所有的变量存储的数据都是加载在内存中,一旦程序结束,数据所占用的内存就被操作系统全部回收。各种类型的数据从内存中变成可存储或传输的过程称之为序列化,序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把数据内容从序列化的对象重新读到内存里称之为反序列化。
序列化的目的:
- 以某种存储形式使自定义对象持久化;
- 将对象可以从一个地方传递到另一个地方;
- 使程序更具有维护性。
在 Python 中,序列化其实就是从其他数据类型转向一个字符串数据类型的过程,而反序列化是从字符串数据类型反向转换成其他数据类型的过程,这里所说的序列其实可以理解为字符串。
在 Python 中为什么要使用序列化模块
当我们在 Python 代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?现在我们能想到的方法就是存在文件里,然后另一个 Python 程序再从文件里读出来。但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。你一定会问,将字典转换成一个字符串很简单,用 str(dic) 就可以办到了,为什么我们还要学习序列化模块呢?
序列化的过程就是从 dic 变成 str(dic) 的过程。现在你可以通过 str(dic) 将一个名为 dic 的字典转换成一个字符串,但是你要怎么把一个字符串转换成字典呢?聪明的你肯定想到了 eval(),如果我们将一个字符串类型的字典 str_dic 传给 eval(),就会得到一个返回的字典类型了。eval() 函数十分强大,但是 eval() 的官方 demo 解释为:将字符串 str 当成有效的表达式来求值并返回计算结果。但是强大的函数有代价,安全性是其最大的缺点。想象一下,如果我们从文件中读出的不是一个数据结构,而是一句类似于 os.remove() 类似的破坏性语句,那么后果将不堪设想。所以,我们并不推荐用 eva() l方法来进行反序列化操作(将 str 转换成 python 中的数据结构)。
Python 中提供了 pickle、json 、 shelve 模块来实现序列化和反序列化。
pickle 模块
使用 pickle 模块可以对所有的 Python 中的数据类型进行序列化和反序列化操作,并且 pickle 序列化的内容只能使用 Python 才能操作,且反序列化依赖代码。
在写入文件时由于 pickle 写入的是二进制数据,所以文件对象打开方式需要用 wb 和 rb 的模式 。下面是 pickle 模块中常用的方法:
dump
1 | pickle.dump(obj, file, protocol=None) |
必备参数 obj 表示将要封装的对象,必备参数 file 表示 obj 要写入的文件对象,file 必须以二进制可写模式打开,即 wb。可选参数 protocol 表示告知 pickler 使用的协议,支持的协议有 0,1,2,3,默认的协议是添加在 Python 3 中的协议 3。例如:
1 | import pickle |
load
1 | pickle.load(file, *, fix_imports=True, encoding="utf-8", errors="strict") |
必备参数 file 必须以二进制可读模式打开,即 rb,其他都为可选参数。例如:
1 | import pickle |
dumps
1 | pickle.dumps(obj, protocol=None) |
以字节对象形式返回封装的对象,不需要写入文件中。例如:
1 | import pickle |
loads
1 | pickle.loads(bytes_object, fix_imports=True, encoding="utf-8", errors="strict") |
从字节对象中读取被封装的对象并返回。例如:
1 | import pickle |
json 模块
json 是一种轻量级的数据交换格式,JSON 数据的书写格式是:名称/值对。名称/值对包括字段名称(在双引号中),然后着是一个冒号(:),最后是值。比如 { "name" : "Python" },类似于Python中的字典。
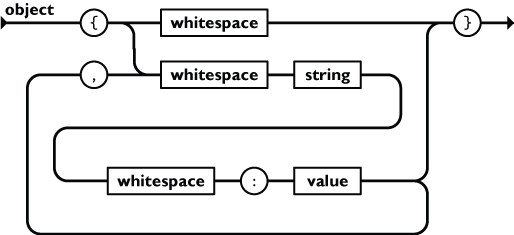
JSON值可以是数字(整数或浮点数),字符串(在双引号中),逻辑值(True 或 False),数组(在中括号中,Python 中是列表),对象(在大括号中)和 null。例如 { "age": 21,"graduated ":true }。JSON值的基本格式如下图所示。
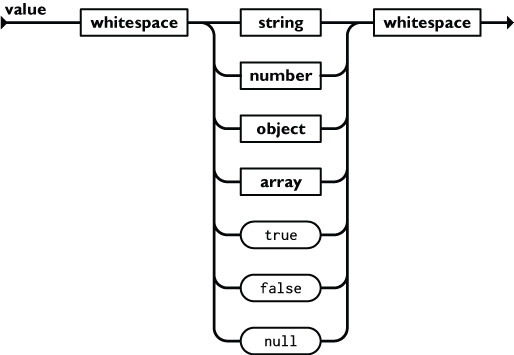
json 作为一种通用的序列化格式具有更好的可读性和跨平台性,但是在 Python 中只有很少一部分数据类型能够通过 json 转化成字符串,不过这已经能能够满足大多数的需求。
json 模块提供了四个方法: dumps、dump、loads、load
在 Python 中其实就是字典格式,里面可以包含方括号括起来的数组,也就是 Python 里面的列表。
dumps 和 loads
dumps 和 loads 都是对内存中的数据进行操作。注意,要用 json 的 loads 功能来处理的 字符串类型的 字典中的字符串必须由 "" 表示。
1 | import json |
对于嵌套的数据类型也是同样适用的:
1 | import json |
dump 和 load
dump 和 load 是对文件对象中的数据进行操作。
1 | #!/usr/bin/env python3 |
其他参数
这里的其他参数是针对 dump 和 dumps 方法而言的。
ensure_ascii:当它为 True 的时候,所有非 ASCII 码字符显示为 \uXXXX 序列,只需在 dump 时将 ensure_ascii 设置为 False 即可,此时存入 json 的字符就会原样输出,包括中文字符。
indent:如果 indent 是一个非负整数或者字符串,那么 JSON 数组元素和对象成员会被美化输出为该值指定的缩进等级。如果缩进等级为零、负数或者 "",则只会添加换行符。如果不设置 indent 则使用默认值 None 以最紧凑的形式来显示。使用一个正整数会让每一层缩进同样数量的空格。如果 indent 的值是一个字符串(比如 "\t"),那么这个字符串会被用于每一层的缩进。
separators:分隔符,实际上是 (item_separator, dict_separator) 的一个元组。当 indent 为 None 时,默认值取 (', ', ': '),否则取 (',', ': ')。为了得到最紧凑的 json 格式的数据,应该指定其为 (',', ':') 以消除空白字符。
默认的就是 (',',':') ;这表示 dictionary 内 keys 之间用 , 隔开,而 key 和 value之间用 : 隔开。
sort_keys:默认为 False,如果设置其值是 true ,那么字典的输出会以键的顺序排序。
Skipkeys:默认值是 False,如果字典的键不是 Python 的基本类型(包括 str, int、float、bool、None),在设置为 Skipkeys=False 时,就会报 TypeError 的错误。此时设置成 True,则会跳过这类 key 。
1 | #!/usr/bin/env python3 |
输出格式:
1 | { |
注意事项
JSON 中的键-值对中的键永远是 str 类型的。当一个对象被转化为 JSON 时,字典中所有的键都会被强制转换为字符串。这所造成的结果是字典被转换为 JSON 然后转换回字典时可能和原来的不相等。换句话说,如果 x 具有非字符串的键,则有 loads(dumps(x)) != x 。
json 和 pickle 的区别
json 和 picle 模块都有 dumps、dump、loads、load 四种方法,而且用法一样。二者不同之处是 json 模块序列化出来的是通用格式,其它编程语言都认识,就是普通的字符串,而 pickle 模块序列化出来的只有 Python 可以认识,其他编程语言无法识别,表现为乱码。
shelve 模块
shelve 模块是 Python3 新出现的方式,特点是操作简单,使用序列化句柄直接操作,非常方便。缺点是目前不太常用。使用 shelve 模块时,通常使用一个 open 方法即可,shelve 以键值对的形式存储数据。
1 | #!/usr/bin/env python3 |
使用 shelve 模块操作文件时 文件最好不要有后缀名,因为 shelve 会生成独有的三个文件。其中以 bak 和 dir 为后缀的文件是可以查看的。
而且 shelve 模块有一个特点就是允许写回(writeback)。在上面的代码中有个细节,我们读取键 person 时候,发现 age 还是 23 岁,f['person']['age'] = 44 后并没有变成 44 。默认情况下直接使用 f['person'] 改变其中的值之后,不会更新已存储的值,也就是没有把更新写回到文件,即使是文件被 close 后。
如果有改变值的需要,在 open 函数中添加一个参数 writeback=True ,再次运行下即可看到 age 的值已经发生了改变。
另外要注意,shelve 模块是有 close 函数的,因此如果不是用 with 方法打开的文件,关闭时需要主动 close 。

