产生背景:
开发人员将测试并运行正常的代码,交给运维人员部署后,部署失败,这就导致了开发人员和运维人员之间因为环境的不同出现很多矛盾,因此慢慢地出现了 DevOps 的概念。所谓的环境不同,指的是不同的操作系统、软件环境、组件版本、应用配置等。
在集群环境下,每台服务器都需要配置相同的环境,配置起来十分麻烦。
解决开发人员常说的 “我不管,在我的机器上是可以正常工作的” 的问题。
Docker 简介
什么是 Docker ?
Docker 是一个开源的应用容器引擎,让开发者可以打包他们开发的应用程序以及程序的依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。
Docker 使用 Google 公司推出的 Go 语言进行开发实现,基于 Linux 内核的 cgroup,namespace,以及 AUFS 类的 Union FS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。由于隔离的进程独立于宿主机和其它的隔离的进程,因此也称其为容器。
Docker 在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护。使得 Docker 技术比虚拟机技术更为轻便、快捷。
容器和虚拟机
下面的图片比较了 Docker 容器技术和传统虚拟机技术的不同之处:
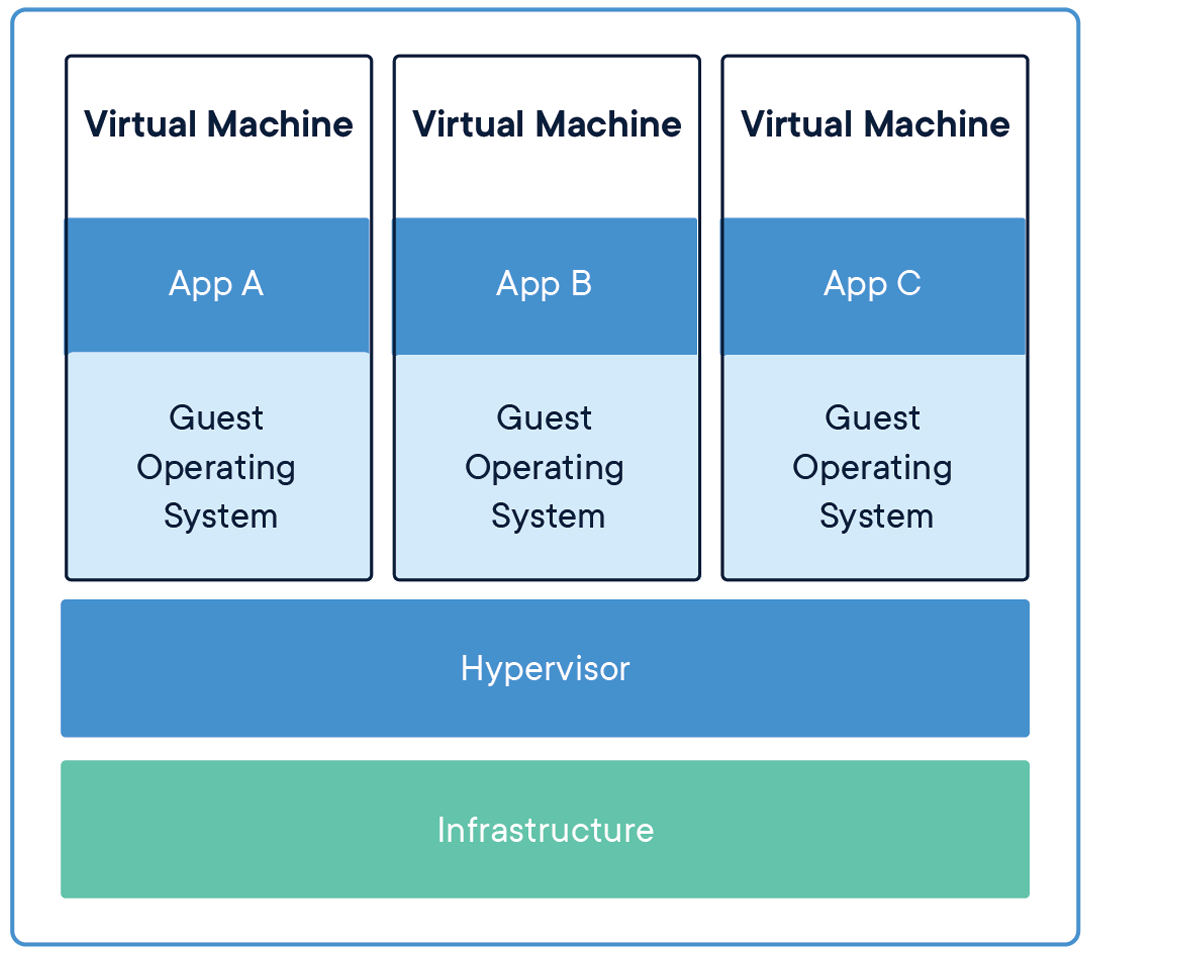
虚拟机(VM)是虚拟出一套硬件(CPU、Memory 等)后,在其上运行一个完整操作系统,它是将一台服务器转变为多台服务器的物理硬件的抽象。系统管理程序允许多个VM在单台计算机上运行。每个VM包含操作系统,应用程序,必要的二进制文件和库的完整副本,这种方式占用大量资源(数十GB),并且VM也可能启动缓慢。
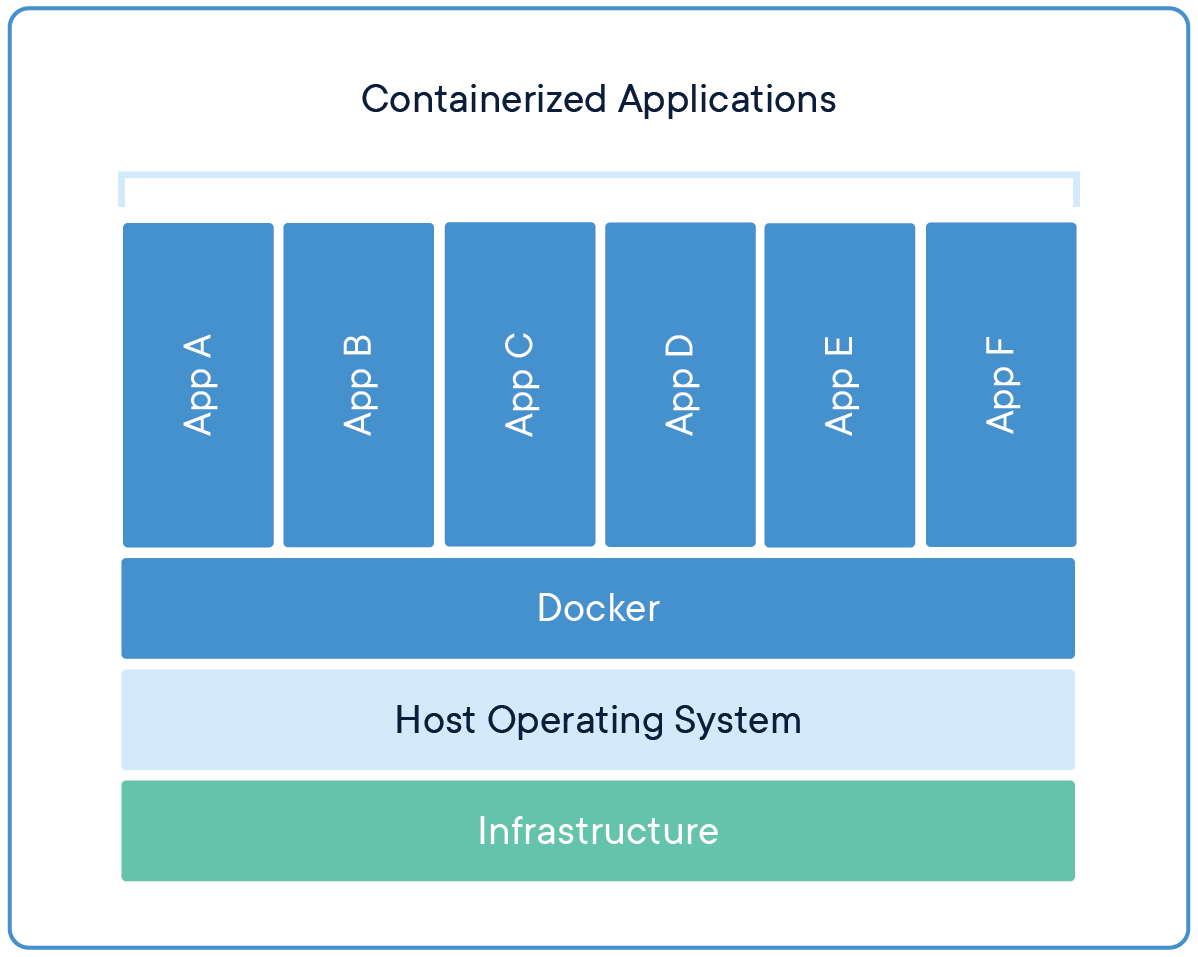
容器将代码和依赖项打包在一起,容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。
多个容器可以在同一台计算机上运行,并与其他容器共享宿主机的内核,每个容器在用户空间中作为隔离的进程运行。容器占用的空间少于VM(容器镜像的大小通常为几十MB),可以处理更多的应用程序,启动速度更快,并且需要的 VM 和操作系统数量更少。
为什么要使用 Docker ?
作为一种新兴的虚拟化方式,Docker 跟传统的虚拟化方式相比具有众多的优势。
更高效的利用系统资源
容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,Docker 对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的物理主机,能运行的容器远大于虚拟机的数量,但是容器不能拿来当作虚拟机给客户使用。
更快速的启动时间
传统的虚拟机技术启动应用服务往往需要数分钟(实际上 OpenStack 虚拟化技术也能达到秒级启动),而 Docker 容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
一致的运行环境
开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而 Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 “这段代码在我机器上没问题啊” 这类问题。
持续交付和部署
对开发和运维(DevOps)人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。开发人员可以通过 Dockerfile 来进行镜像构建,并结合 持续集成(Continuous Integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合 持续部署(Continuous Delivery/Deployment) 系统进行自动部署。而且使用 Dockerfile 使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像。
更轻松的迁移
由于 Docker 确保了执行环境的一致性,使得应用的迁移更加容易。Docker 可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的。因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
更轻松的维护和扩展
Docker 使用的分层存储以及镜像的技术,使得应用重复部分的复用更为容易,也使得应用的维护更新更加简单,基于基础镜像进一步扩展镜像也变得非常简单。此外,Docker 团队同各个开源项目团队一起维护了一大批高质量的 官方镜像,既可以直接在生产环境使用,又可以作为基础进一步定制,大大的降低了应用服务的镜像制作成本。
容器技术对比传统虚拟机总结
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘 | 使用一般为 MB | 一般为 GB |
| 性能 | 接近原生 | 弱于原生 |
| 系统 | 支持量单机支持上千个容器 | 一般几十个 |
容器技术属于进程之间的隔离,虚拟机技术可以实现系统级别隔离。物理机没有快照的概念,虚拟机的快照功能极大的提高了容灾性、数据备份等功能。我们可以授权给容器来操作宿主机,而虚拟机是无法操作宿主机的。
总而言之,容器技术虽然比虚拟机技术有着更多的优点,但是容器和虚拟机一起使用,在部署和管理应用程序时提供了很大的灵活性。
基本概念
Docker Host:安装了 Docker 程序的主机,运行 Docker 守护进程
Docker Image:镜像,将软件环境打包好的模板,用来创建容器的,一个镜像可以创建多个容器。
Docker Container:容器,运行镜像后生成的实例称为容器,每运行一次镜像就会产生一个容器,容器可以启动、停止或删除。容器使用是沙箱机制,互相隔离,是独立是安全的。可以把容器看作是一个简易版的 Linux 环境,包括用户权限、文件系统和运行的应用等。
Docker Repository:仓库,用来保存镜像,仓库中包含许多镜像,每个镜像都有不同的标签 Tag,在 官方仓库 中可以搜索出很多镜像。
安装 Docker
Docker 划分为 CE 和 EE。CE 即社区版(免费,支持周期三个月),EE 即企业版,强调安全,付费使用。在官方网站上有各种环境下的 安装指南 。
由于各项新技术(Systemd、Cgroup 等)的出现,以及容器技术的优势和不断成熟,进一步促进了内核更新,为了对容器技术有着更好的支持。建议使用较新版本的 Linux 系统,这里以 Docker CE 在 CentOS7 上的安装为例。
Docker CE 支持 64 位版本 CentOS 7,并且要求内核版本不低于 3.10。 CentOS 7 满足最低内核的要求,但由于内核版本比较低,部分功能(如 overlay2 存储层驱动)无法使用,并且部分功能可能不太稳定。
系统环境的配置
运行环境配置
时区,selinux、系统运行级别等的配置。
1 | # Set timezone |
系统服务配置
firewalld 功能更强大,但是生成的防火墙规则和链比较繁琐,使用 iptables 命令完全够用,这里将其停止并禁止开机自启:
1 | systemctl disable --now firewalld.service |
NetworkManager 服务早期一直用来管理图形化界面 Linux 的网络,从 CentOS8 开始,它已经完全取代了 network 服务,并且使用 nmcli 命令来管理非图形化界面 Linux 的网络。因此不建议对 NetworkManager 做操作,如果对 NetworkManager 比较了解,你也可以选择在 CentOS7 上将其关停:
1 | systemctl disable --now NetworkManager.service |
在图形界面 Linux 上默认会安装 Dnsmasq 来配置本地自有 DNS 服务器,这有可能会导致 nameserver 被设置为 127.0.0.1,从而导致容器无法解析域名。因此将其关停:
1 | systemctl disable --now dnsmasq.service |
资源使用限定
默认的 limit 数值较小,手动改 /etc/security/limits.conf 或在 /etc/security/limits.d/ 创建自定义配置文件,来修改资源的限定:
1 | # Modify shell resource limits |
对 Systemd 的资源使用做设置:
1 | # Modify systemd resource limits |
内核参数设置
设置 iptables 不对 bridge 的数据进行处理:
1 | cat << EOF > /etc/sysctl.d/docker.conf |
修改内核的环境变量配置文件 /etc/default/grub,在 GRUB_CMDLINE_LINUX= 中启用内核的 user_namespaces :
1 | cp /boot/grub2/grub.cfg{,.old}; |
使用 grubby 命令也可以直接修改 /boot/grub2/grub.cfg 中的 grub 策略:
1 | grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)" |
注意: 这并不会更新 /etc/default/grub ,所以最稳妥的办法还是修改 /etc/default/grub 然后重新生成配置。
配置完成后需要重启系统才能让参数生效:
1 | systemctl reboot |
安装 Docker
官方提供了配置检查脚本,用来检查环境是否符合要求:
1 | curl -s https://raw.githubusercontent.com/docker/docker/master/contrib/check-config.sh -o check-config.sh |
使用官方脚本安装,为了有更快的速度,可以将镜像下载源指定为 Aliyun :
1 | curl -fsSL https://get.docker.com -o get-docker.sh && sh get-docker.sh --mirror Aliyun |
安装完成后查看版本,验证安装是否成功:
1 | docker version |
后续配置
安装 bash 补全包,安装后可以为 systemd 、ip 、 docker 等命令做子命令的补全,当然还可以自定义。
1 | yum -y install bash-completion |
安装完成后重新登录机器即可生效,如果未生效则可以拷贝 Docker 自己生成的补全脚本到系统的 bash 补全配置目录下:
1 | cp -a /usr/share/bash-completion/completions/docker ${BASH_COMPLETION_COMPAT_DIR}/ |
配置 Docker 守护进程
官方文档:
常用配置:
网络:
- 默认情况下 docker0 网卡分配的 IP 地址是
172.17.0.1,所在的地址段是172.17.0.0/16, 如果有冲突可以自行定义。 - DNS:如果不想让 Docker 使用主机的
nameserver,可以使用dns来指定自定义的 DNS 服务器。
- 默认情况下 docker0 网卡分配的 IP 地址是
存储驱动:
- 默认存储引擎和受支持的存储引擎列表取决于主机的 Linux 发行版和可用的内核驱动程序,建议使用
overlay2,详情请看 官方扫盲。 - 允许覆盖 overlay2 的 Linux 内核版本检查:在 4.0.0 版本内核中,添加了对 overlay2 所需的多个较低目录的支持。但是,可能会修补某些较旧的内核版本,以添加对 OverlayFS 的多个较低目录支持。仅在验证内核中存在此支持后,才应使用此选项。在没有此支持的情况下在内核上应用此选项将导致安装失败。
- 默认存储引擎和受支持的存储引擎列表取决于主机的 Linux 发行版和可用的内核驱动程序,建议使用
日志驱动:
- Docker 提供了通过一系列日志记录驱动程序,用来收集和查看主机上运行的所有容器的日志数据。默认的日志记录驱动程序
json-file将日志数据写入主机文件系统上的 JSON 格式的文件。 - 日志轮转:随着时间的推移,这些日志文件的大小会扩大,从而可能导致磁盘资源耗尽。要缓解此类问题,请配置备用日志记录驱动程序(例如 Splunk 或 Syslog ),或为默认驱动程序设置日志轮转。
- Docker 提供了通过一系列日志记录驱动程序,用来收集和查看主机上运行的所有容器的日志数据。默认的日志记录驱动程序
runtime:使用
--exec-opt标志指定的选项来配置 runtime。所有标志的选项都有native前缀,有一个native.cgroupdriver选项可用。该选项指定用什么来进行容器的 cgroup 管理。只能指定cgroupfs或systemd。如果指定systemd并且不可用,则系统会出错。如果没有配置native.cgroupdriver选项,则使用cgroupfs进行管理。
1 | mkdir -pv /etc/docker/ |
配置 Docker 镜像加速器
国内访问 Docker Hub 下载镜像有时候会比较慢,此时可以配置镜像加速器。国内一些云服务商提供了容器镜像加速服务,例如:
如果网络质量较好,这一步可以忽略不做。以阿里云为例,以下是配置步骤:
1、注册并登录 “阿里云的容器镜像服务控制台” https://cr.console.aliyun.com/
2、查看专属的加速器地址。
3、配置自己的 Docker 加速器,注意一定要保证该文件符合 json 规范,否则 Docker 将不能启动。
1 | vim /etc/docker/daemon.json |
检查加速器是否生效:配置加速器之后,如果拉取镜像仍然十分缓慢,请手动检查加速器配置是否生效,在命令行
执行 docker info ,如果从结果中看到了如下内容,说明配置成功:
1 | Registry Mirrors: |
使用 Systemd 控制 Docker
将 docker 设置为开机自启,并启动该服务程序:
1 | systemctl enable --now docker.service |
查看服务的运行状态:
1 | systemctl status docker.service |
使用镜像
Docker 运行容器前需要本地存在对应的镜像,如果本地不存在该镜像,Docker 会从镜像仓库下载该镜像。
查找镜像
Docker 提供了一个官方专业存放镜像的地方,即镜像仓库 Docker Hub,在这上面有大量的高质量的镜像可以使用。打开 Docker Hub 后点击 “Explore” 即可进入仓库列表页面。
在搜索框可以输入相关的镜像名称进行搜索,以 Nginx 为例,在搜索到的镜像中会有 “Tags” 按钮,这就是镜像的标签列表,标签表示了不同的版本。
为什么要有标签呢?镜像 = <仓库>:[Tag]。一个 Docker Registry 中可以包含多个仓库 (Repository);每个仓库可以包含多个标签 (Tag);每个标签对应一个镜像 (Image)。
在命令行可以使用 docker search 进行搜索,命令基本语法为:
1 | docker search [选项] <镜像ID/镜像名称>[:标签] |
其中 [] 表示可选,<> 表示必选。镜像名称一般为 “<用户名>/<软件名>”,只有软件名的一般是官方镜像。
1 | [root@bogon ~]# docker search nginx |
从上面的命令执行的结果中,并不能看到镜像的标签,所以要下载特定镜像还需要在网页上搜索查找。
获取镜像
从 Docker 镜像仓库获取镜像的命令是 docker pull 。其命令格式为:
1 | docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签] |
镜像名称的格式:
Docker 镜像仓库地址:地址的格式一般是
<域名/IP>[:端口号]。默认地址是 Docker Hub。仓库名:如之前所说,这里的仓库名是两段式名称,即
<用户名>/<软件名>。对于 Docker Hub,如果不给出用户名,则默认为 library ,也就是官方镜像。
下面的命令中没有给出 Docker 镜像仓库地址,因此将会从 Docker Hub 获取镜像。而镜像名称是 nginx:latest ,因此将会获取官方镜像 library/nginx 仓库中标签为 latest 的镜像:
1 | docker pull nginx:latest |
从下载过程中可以看到分层存储的概念,镜像是由多层存储所构成。下载也是一层层的去下载,并非单一文件。下载过程中给出了每一层的 ID 的前 12 位。并且下载结束后,给出该镜像完整的 sha256 的摘要信息,以确保下载一致性。
有可能你看到的层 ID 以及 sha256 的摘要和这里的不一样。这是因为官方镜像是一直在维护的,有任何新的 bug,或者版本更新,都会进行修复再以原来的标签发布,这样可以确保任何使用这个标签的用户可以获得更安全、更稳定的镜像。
列出镜像
要想列出已经下载下来的镜像,可以使用 docker image ls 命令或 docker images 命令。
1 | [root@bogon ~]# docker image ls |
不加任何参数则列出所有镜像,也可以指定镜像:
1 | [root@bogon ~]# docker image ls ubuntu |
列表包含了 仓库名 、 标签 、 镜像 ID 、 创建时间 以及 所占用的空间 。其中 镜像 ID 是镜像的唯一标识,一个镜像可以对应多个标签。因此,在上面命令执行结果中,可以看到 ubuntu:18.04 和 ubuntu:latest 拥有相同的 ID,因为它们对应的是同一个镜像。
镜像体积
在 Docker Hub 中显示的镜像的体积是压缩后的体积。在镜像下载和上传过程中镜像是保持着压缩状态的,因此 Docker Hub 所显示的大小是网络传输中更关心的流量大小。而 docker image ls 显示的是镜像下载到本地后,展开的大小,准确说,是展开后的各层所占空间的总和,因为镜像到本地后,查看空间的时候,更关心的是本地磁盘空间占用的大小。
另外一个需要注意的问题是, docker image ls 列表中的镜像体积总和并非是所有镜像实际硬盘消耗。由于 Docker 镜像是多层存储结构,并且可以继承、复用,因此不同镜像可能会因为使用相同的基础镜像,从而拥有共同的层。由于 Docker 使用 Union FS,相同的层只需要保存一份即可,因此实际镜像硬盘占用空间很可能要比这个列表镜像大小的总和要小的多。
使用 docker system df 命令可以便捷地查看镜像、容器、数据卷所占用的空间。
1 | [root@bogon ~]# docker system df |
虚悬镜像
在镜像列表中,有可能看到特殊的镜像,既没有仓库名,也没有标签,均为 <none> 。这种镜像原本是有镜像名和标签的,比如原来为 mongo:3.2 ,随着官方镜像维护,发布了新版本后,重新 docker pull mongo:3.2 时,mongo:3.2 这个镜像名被转移到了新下载的镜像身上,而旧的镜像上的这个名称则被取消,从而成为了 <none> 。除了 docker pull 可能导致这种情况, docker build 也同样可以导致这种现象。由于新旧镜像同名,旧镜像名称被取消,从而出现仓库名、标签均为 <none> 的镜像。这类无标签镜像也被称为 虚悬镜像 (dangling image) ,可以用下面的命令专门显示这类镜像:
1 | docker image ls --filter dangling=true |
一般来说,虚悬镜像已经失去了存在的价值,是可以随意删除的,可以用下面的命令删除没有被使用到的镜像。
1 | docker image prune |
中间层镜像
为了加速镜像构建、重复利用资源,Docker 会利用中间层镜像。所以在使用一段时间后,可能会看到一些依赖的中间层镜像。默认的 docker image ls 列表中只会显示顶层镜像,如果希望显示包括中间层镜像在内的所有镜像的话,需要加 -a 参数。
1 | docker image ls -a |
这样会看到很多无标签的镜像,与之前的虚悬镜像不同,这些无标签的镜像很多都是中间层镜像,是其它镜像所依赖的镜像。这些无标签镜像不应该删除,否则会导致上层镜像因为依赖丢失而出错。实际上,这些镜像也没必要删除,因为相同的层只会存一遍,而这些镜像是别的镜像的依赖,因此并不会因为它们被列出来而多存了一份。删除镜像后,依赖的中间层镜像也会被连带删除。
列出部分镜像
不加任何参数的情况下, docker image ls 会列出所有顶级镜像,但是有时候我们只希望列出部分镜像。 docker image ls 有好几个参数可以帮助做到这个事情。
根据仓库名列出镜像:
1 | [root@bogon ~]# docker image ls ubuntu |
列出特定的某个镜像,也就是说指定仓库名和标签:
1 | [root@bogon ~]# docker image ls ubuntu:18.04 |
除此以外, docker image ls 还支持强大的过滤器参数 --filter ,或者简写 -f 。之前使用过滤器来列出虚悬镜像的用法:
1 | docker image ls --filter dangling=true |
如果想要看到在 ubuntu:19.04 之后建立的镜像,可以用下面的命令:
1 | [root@bogon ~]# docker image ls --filter since=ubuntu:19.04 |
想查看某个位置之前的镜像,只需要把 since 换成 before 即可。此外,如果镜像构建时,定义了 LABEL ,还可以通过 LABEL 来过滤。
1 | docker image ls --filter label=com.example.version=0.1 |
以特定格式显示
默认情况下, docker image ls 会输出一个完整的表格,但是并非所有时候都会需要这些内容。比如,删除虚悬镜像的时候,需要利用 docker image ls 把所有的虚悬镜像的 ID 列出来,然后才可以交给 docker image rm 命令作为参数来删除指定的这些镜像,这时候就用到了 -q 参数。
1 | [root@bogon ~]# docker image ls -q |
使用 --filter 配合 -q 产生出指定范围的 ID 列表,然后送给另一个 docker 命令作为参数,从
而针对这组实体成批的进行某种操作。这种做法在 Docker 命令行使用过程中非常常见,不仅仅是
镜像命令,在各个命令中都可以使用这类搭配以完成很强大的功能。
1 | [root@bogon ~]# docker image ls --filter since=nginx:latest |
如果只是对表格的结构不满意,希望自己组织列;或者不希望有标题,这样方便其它程序解析结果等,这就用到了 Go 的模板语法。比如只接列出镜像结果,并且只包含镜像ID和仓库名:
1 | [root@bogon ~]# docker image ls --format "{{.ID}}: {{.Repository}}" |
如果想要以表格等距显示,并且有标题行,和默认一样,但是想定义列:
1 | [root@bogon ~]# docker image ls --format "table {{.ID}}\t{{.Repository}}\t{{.Tag}}\t{{.Size}}" |
删除本地镜像
如果要删除本地的镜像,可以使用 docker image rm 命令,其格式为:
1 | $ docker image rm [选项] <镜像1> [<镜像2> ...] |
用 ID、镜像名、摘要删除镜像
其中, <镜像> 可以是 镜像短 ID 、 镜像长 ID 、 镜像名 或者 镜像摘要 。可以用镜像的完整 ID,也称为 长 ID ,来删除镜像,但是更多的时候是用 短 ID 来删除镜像。
默认情况下 docker image ls 列出的是短 ID ,一般取前3个字符以上,只要足够区分于别的镜像即可。
1 | [root@bogon ~]# docker image ls redis |
比如要删除 redis:alpine 镜像:
1 | docker image rm a49ff3e0d85f |
也可以用 镜像名 ,也就是 <仓库名>:<标签> 来删除镜像:
1 | docker image rm redis:latest |
当然,更精确的是使用 镜像摘要 删除镜像。
1 | [root@bogon ~]# docker image ls --digests --format "table{{.ID}}\t{{.Digest}}\t{{.Repository}}\t{{.Tag}}" redis |
Untagged 和 Deleted
删除行为分为两类,一类是 Untagged ,另一类是 Deleted 。镜像的唯一标识是其 ID 和摘要,而一个镜像可以有多个标签。
1 | [root@bogon ~]# docker image ls redis |
因此当删除镜像的时候,实际上是在要求删除某个标签的镜像。所以首先需要做的是将满足要求的所有镜像标签都取消,这就是我们看到的 Untagged 的信息。因为一个镜像可以对应多个标签,因此当我们删除了所指定的标签后,可能还有别的标签指向了这个镜像,如果是这种情况,那么 Delete 行行为就不会发生。所以并非所有的 docker rm 都会产生删除镜像的行为,有可能仅仅是取消了某个标签而已。
当该镜像所有的标签都被取消了,该镜像很可能会失去了存在的意义,因此会触发删除行为。镜像是多层存储结构,因此在删除的时候也是从上层向基础层方向依次进行判断删除。镜像的多层结构让镜像复用变动非常容易,因此很有可能某个其它镜像正依赖于当前镜像的某一层。这种情况,依旧不会触发删除该层的行为。直到没有任何层依赖当前层时,才会真实的删除当前层。这就是有时候明明没有别的标签指向这个镜像,但是它还是存在的原因,也是为什么有时候会发现所删除的层数和自己 docker pull 看到的层数不一样的原因。
除了镜像依赖以外,还需要注意的是容器对镜像的依赖。如果有用这个镜像启动的容器存在(即使容器没有运行),那么同样不可以删除这个镜像。容器是以镜像为基础,再加一层容器存储层,组成这样的多层存储结构去运行的。因此该镜像如果被这个容器所依赖的,那么删除必然会导致故障。如果这些容器是不需要的,应该先将它们删除,然后再来删除镜像。
用 docker image ls 命令来配合
使用 docker image ls -q 来配合使用 docker image rm ,可以批量删除镜像。比如,要删除所有仓库名为 redis 的镜像:
1 | docker image rm $(docker image ls -q redis) |
或者删除所有在 mongo:3.2 之前的镜像:
1 | docker image rm $(docker image ls -q --filter before=mongo:3.2) |
CentOS/RHEL 的注意事项
在 Ubuntu/Debian 上有 UnionFS 可以使用,如 aufs 或者 overlay2 ,而 CentOS 和 RHEL 的内核中没有相关驱动。因此对于这类系统,一般使用 devicemapper 驱动利用 LVM 的一些机制来模拟分层存储。这样的做法除了性能比较差外,稳定性一般也不好,而且配置相对复杂。Docker 安装在 CentOS/RHEL 上后,会默认选择 devicemapper ,但是为了简化配置,其 devicemapper 是跑在一个稀疏文件模拟的块设备上,也被称为 loop-lvm 。这样的选择是因为不需要额外配置就可以运行 Docker,这是自动配置唯一能做到的事情。但是 loop-lvm 的做法非常不好,其稳定性、性能更差,无论是日志还是 docker info 中都会看到警告信息。官方文档有明确的文章讲解了如何配置块设备给 devicemapper 驱动做存储层的做法,这类做法也被称为配置 direct-lvm 。
除了前面说到的问题外, devicemapper + loop-lvm 还有一个缺陷,因为它是稀疏文件,所以它会不断增长。用户在使用过程中会注意到 /var/lib/docker/devicemapper/devicemapper/data 不断增长,而且无法控制。很多人会希望删
除镜像或者可以解决这个问题,结果发现效果并不明显。原因就是这个稀疏文件的空间释放后基本不进行垃圾回收的问题。因此往往会出现即使删除了文件内容,空间却无法回收,只能随着使用这个稀疏文件一直在不断增长。所以对于 CentOS/RHEL 的用户来说,在没有办法使用 UnionFS 的情况下,一定要配置 direct-lvm 给 devicemapper ,无论是为了性能、稳定性还是空间利用率。或许有人注意到了 CentOS 7 中存在被 backports 回来的 overlay 驱动,不过 CentOS 里的这个驱动达不到生产环境使用的稳定程度,所以不推荐使用。
操作容器
启动容器
启动容器有两种方式,一种是基于镜像新建一个容器并启动,另外一个是将在终止状态( stopped )的容器重新启动。
新建并启动
所需要的命令主要为 docker run 。例如运行一个容器,执行 echo 命令输出一个 “Hello World”,之后终止容器:
1 | [root@bogon ~]# docker run centos:latest /bin/echo "Hello World" |
如果要为容器分配一个伪终端,并进入用户交互式的 bash 终端:
1 | [root@bogon ~]# docker run --tty --interactive centos /bin/bash |
其中, --tty 选项让 Docker 分配一个伪终端(pseudo-tty)并绑定到容器的标准输入上, --interactive 则让容器的标准输入保持打开。
在交互模式下,用户可以通过所创建的终端来输入命令,例如:
1 | [root@876dabff426e /]# uname -r |
当利用 docker run 来创建容器时,Docker 在后台运行的标准操作包括:
检查本地是否存在指定的镜像,不存在就从公有仓库下载。
利用镜像创建并启动一个容器。
分配一个文件系统,并在只读的镜像层外面挂载一层可读写层。
从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去。
从地址池配置一个 ip 地址给容器。
执行用户指定的应用程序。
执行完毕后容器被终止。
启动已终止容器
可以利用 docker container start 命令,指定容器名字或者容器 ID 来直接将一个已经终止的容器启动运行。
容器的核心为所执行的应用程序,所需要的资源都是应用程序运行所必需的。除此之外,并没有其它的资源。可以在伪终端中利用 ps 或 top 来查看进程信息。
1 | [root@bogon ~]# docker run --tty --interactive centos /bin/bash |
可见,容器中仅运行了指定的 bash 进程。这种特点使得 Docker 对资源的利用率极高,是货真价实的轻量级虚拟化。
后台运行
多数情况下,需要让 Docker 在后台运行而不是直接把执行命令的结果输出在当前宿主机下。此时,可以通过添加 -d 参数来实现。
如果不使用 -d 参数运行容器,容器会把输出的结果 (STDOUT) 打印到宿主机上面:
1 | [root@bogon ~]# docker run centos /bin/bash -c 'for i in {1..10}; do echo ${i}: hello world; sleep 1; done' |
如果使用了 -d 参数运行容器,此时容器会在后台运行并不会把输出的结果 (STDOUT) 打印到宿主机上面(输出结果可以用 docker container logs 查看)。
1 | [root@bogon ~]# docker run -d centos /bin/bash -c 'for i in {1..10}; do echo ${i}: hello world; sleep 1; done' |
注意: 容器是否会长久运行,和 docker run 指定的命令有关,和 -d 参数无关。
使用 -d 参数启动后会返回一个唯一的 id,也可以通过 docker container ls 或 docker ps 命令来查看容器信息。
终止容器
可以使用docker container stop 来终止一个运行中的容器。
此外,当 Docker 容器中指定的应用程序停止运行时,容器也自动终止。终止状态的容器可以用 docker container ls -a 命令看到。
1 | [root@bogon ~]# docker container ls |
处于终止状态的容器,可以通过 docker container start 命令来重新启动。如果使用 docker container restart 命令,则会将一个运行态的容器终止,然后再重新启动它。
进入容器
在使用 -d 参数时,容器启动后会进入后台运行,某些时候需要进入容器进行操作,这时候就要用到 docker attach 命令或 docker exec 命令,建议使用 docker exec 命令,原因会在下面说明。
attach 命令
docker attach 是 Docker 自带的命令。
1 | [root@bogon ~]# docker run -d --interactive --tty ubuntu |
注意: 如果从这个 stdin 中 exit,会导致容器的停止。
exec 命令
使用 docker exec 命令,后边可以跟多个参数,这里主要说明 --interactive --tty 参数。
在
exec后只用--interactive参数时,由于没有分配伪终端,界面没有我们熟悉的 Linux 命令提示符,但命令执
行结果仍然可以返回。当
--interactive--tty参数一起使用时,则可以看到我们熟悉的 Linux 命令提示符。
1 | [root@bogon ~]# docker run -d --interactive --tty ubuntu |
如果从这个 stdin 中 exit,不会导致容器的停止。这就是为什么建议使用 docker exec 。
导出和导入容器
导出容器
如果要导出本地某个容器,可以使用 docker export 命令。
1 | [root@bogon ~]# docker ps -a |
这样将导出容器快照到本地文件。
导入容器快照
可以使用 docker import 从容器快照文件中再导入为镜像,例如:
1 | [root@bogon ~]# docker import ubuntu.tar |
还可以通过指定 URL 或者某个目录来导入,例如:
1 | docker import http://example.com/exampleimage.tgz example/imagerepo |
注意:用户既可以使用 docker load 来导入镜像存储文件到本地镜像库,也可以使用 docker
import 来导入一个容器快照到本地镜像库。这两者的区别在于容器快照文件将丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态),而镜像存储文件将保存完整记录,体积也要大。此外,从容器快照文件导入时可以重新指定标签等元数据信息。
删除
删除容器
可以使用 docker container rm 来删除一个或多个处于终止状态的容器。例如:
1 | [root@bogon ~]# docker ps -a --filter exited=0 |
如果要删除一个运行中的容器,可以添加 -f 参数。Docker 会发送 SIGKILL 信号给容器。
1 | [root@bogon ~]# docker ps |
清理所有处于终止状态的容器用 docker ps -a 命令可以查看所有已经创建的包括终止状态的容器,如果数量太多要一个个删除可能会很麻烦,用下面的命令可以清理掉所有处于终止状态的容器。
1 | docker container prune |
构建镜像
利用 commit 理解镜像构成
注意: docker commit 命令除了学习之外,还有一些特殊的应用场合,比如被入侵后保存现场等。但是,不要使用 docker commit 定制镜像,定制镜像应该使用 Dockerfile 来完成。
镜像是容器的基础,每次执行 docker run 的时候都会指定哪个镜像作为容器运行的基础。镜像是多层存储,每一层是在前一层的基础上进行的修改;而容器同样也是多层存储,是在以镜像为基础层,在其基础上加一层作为容器运行时的存储层。以定制一个 Web 服务器为例,来认识镜像是如何构建的。
1 | docker run --name WebServer01 -d -p 80:80 nginx |
这条命令会用 nginx 镜像启动一个容器,命名为 WebServer01 ,并且把宿主机的 80 端口映射到了容器的 80 端口,这样用浏览器访问宿主机就会被映射到容器了。
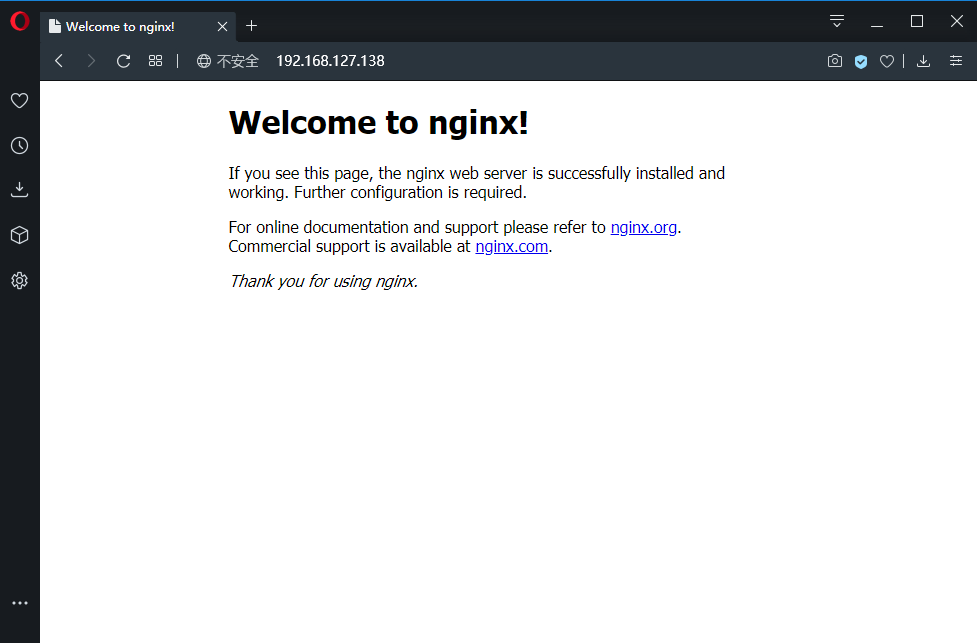
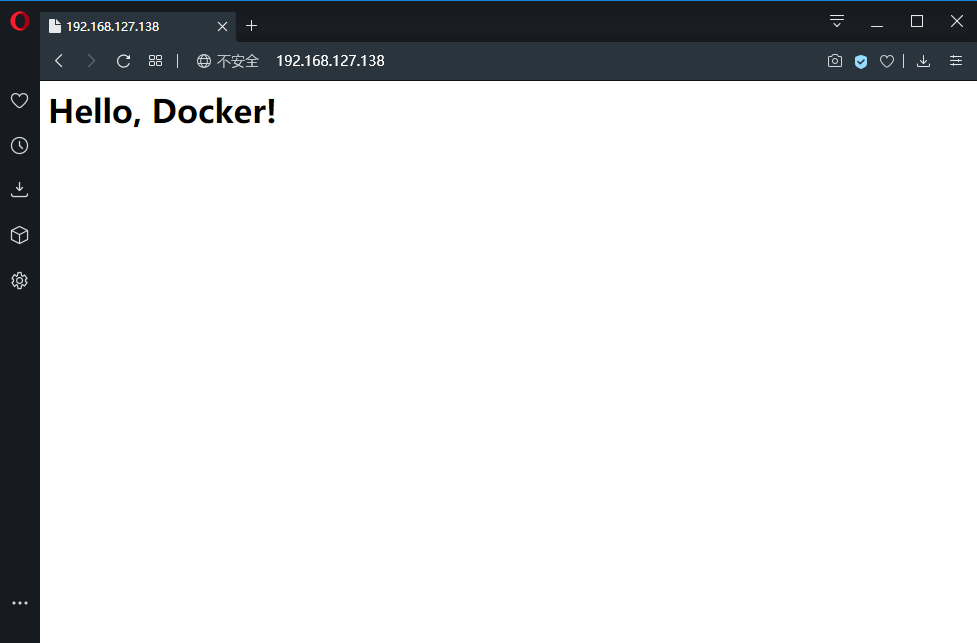
直接用浏览器访问的会看到默认的 Nginx 欢迎页面。现在,假设想要修改这个欢迎页面,改成欢迎 Docker 的文字,可以使用 docker exec 命令进入容器,修改其内容。
1 | [root@bogon ~]# docker exec --interactive --tty WebServer01 /bin/bash |
上面的命令时以交互式终端方式进入 WebServer01 容器,并执行了 /bin/bash 命令,也就是获得一个可操作的 Shell 。然后,我们用 <h1>Hello, Docker!</h1> 覆盖了 /usr/share/nginx/html/index.html 的内容。再刷新浏览器会发现内容被改变了。
修改了容器的文件,也就是改动了容器的存储层。可以通过 docker diff 命令看到具体的改动。
1 | [root@bogon ~]# docker diff WebServer01 |
现在定制好了变化,我们希望能将其保存下来形成镜像。当运行一个容器的时候(如果不使用卷的话),在容器中做的任何文件修改都会被记录于容器存储层里。而 Docker 提供了一个 docker commit 命令,可以将容器的存储层保存下来成为镜像。换句话说,就是在原有镜像的基础上,再叠加上容器的存储层,并构成新的镜像。以后运行这个新镜像的时候,就会拥有原有容器最后的文件变化。
docker commit 的语法格式为:
1 | docker commit [选项] <容器ID或容器名> [<仓库名>[:<标签>]] |
可以用下面的命令将容器保存为镜像:
1 | [root@bogon ~]# docker commit --author "Silence" --message "修改了默认欢迎页" WebServer01 nginx:v1.1 |
其中 --author 是指定修改的作者,而 --message 则是记录本次修改的内容。这和 git 版本控制相似,不过这里这些信息可以省略不写。使用 docker image ls 可以看到这个新定制的镜像:
1 | [root@bogon ~]# docker image ls nginx |
还可以用 docker image history 具体查看镜像内的历史记录,如果比较 nginx:latest 的历史记录,可以发现新增了刚刚提交的这一层。
1 | [root@bogon ~]# docker image history nginx:v1.1 |
新的镜像定制好后,就可以来运行这个镜像了:
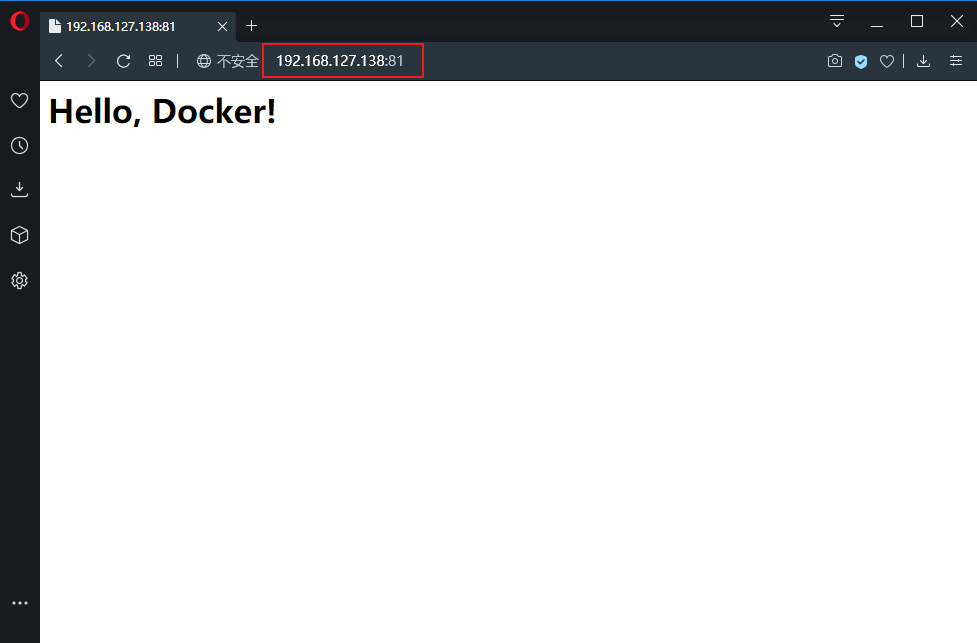
1 | docker run --name WebServer02 -d -p 81:80 nginx:v1.1 |
这里容器命名为新的服务为 WebServer02 ,并且映射宿主机 81 端口到容器的 80 端口。在浏览器直接访问看到的结果,其内容应该和之前修改后的 WebServer01 一样。
慎用 docker commit
使用 docker commit 命令虽然可以比较直观地帮助理解镜像分层存储的概念,但是生产环境中并不会这样使用。
首先,如果仔细观察之前的 docker diff WebServer01 的结果,会发现除了真正想要修改的 /usr/share/nginx/html/index.html 文件外,由于命令的执行,还有很多文件被改动或添加了。这仅仅是最简单的操作,如果是安装软件包、编译构建,就会有大量的无关内容被添加进来,如果不小心清理,将会导致镜像非常臃肿。
此外,使用 docker commit 意味着所有对镜像的操作都是黑箱操作,生成的镜像也被称为黑箱镜像,换句话说,就是除了制作镜像的人知道执行过什么命令、怎么生成的镜像,别人根本无从得知。而且,即使是这个制作镜像的人,过一段时间后也无法记清具体在操作的。虽然 docker diff 或许可以告诉得到一些线索,但是远远不到可以确保生成一致镜像的地步。这种黑箱镜像的维护工作是非常痛苦的。
而且,按照镜像所使用的分层存储的概念,除当前层外,之前的每一层都是不会发生改变的,换句话说,任何修改的结果仅仅是在当前层进行标记、添加、修改,而不会改动上一层。如果使用 docker commit 制作镜像,以及后期修改的话,每一次修改都会让镜像更加臃肿一次,所删除的上一层的东西并不会丢失,会一直如影随形的跟着这个镜像,即使根本无法访问到。这会让镜像更加臃肿。
使用 Dockerfile 定制镜像
镜像的定制实际上就是定制每一层所添加的配置、文件。如果可以把每一层修改、安装、构建、操作的命令都写入一个脚本,用这个脚本来构建、定制镜像,那么之前提及的无法重复的问题、镜像构建透明性的问题、体积的问题就都会解决。这个脚本就是 Dockerfile。
Dockerfile 是一个文本文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。还以定制 Nginx 镜像为例,现在使用 Dockerfile 来定制。
在一个空白目录中,建立一个文本文件,并命名为 Nginx-Dockerfile :
1 | [root@bogon ~]# mkdir -pv mynginx |
其内容为:
1 | FROM nginx |
FROM 指定基础镜像
定制镜像,是以一个镜像为基础,在其之上进行定制。就像之前运行了一个 nginx 镜像的容器,再进行修改一样,基础镜像是必须指定的。而 FROM 就是指定基础镜像,因此一个 Dockerfile 中 FROM 是必备的指令,并且必须是第一条指令。
在 Docker Hub 上有非常多的高质量的官方镜像,有可以直接拿来使用的服务类的镜像,如 nginx 、 redis 、 mongo 、 mysql 、 httpd 、 php 、 tomcat 等;也有一些方便开发、构建、运行各种语言应用的镜像,如 node 、 openjdk 、 python 、 ruby 、 golang 等。可以在其中寻找一个最符合我们最终目标的镜像为基础镜像进行定制。如果没有找到对应服务的镜像,官方镜像中还提供了一些更为基础的操作系统镜像,如 ubuntu 、 debian 、 centos 、 fedora 、 alpine 等,这些操作系统的软件库为提供了更广阔的扩展空间。
除了选择现有镜像为基础镜像外,Docker 还存在一个特殊的镜像,名为 scratch 。这个镜像是虚拟的概念,并不实际存在,它表示一个空白的镜像。
1 | FROM scratch |
如果以 scratch 为基础镜像,意味着不以任何镜像为基础,接下来所写的指令将作为镜像第一层开始存在。
不以任何系统为基础,直接将可执行文件复制进镜像的做法并不罕见,比如 swarm 、 coreos/etcd 。对于 Linux 下静态编译的程序来说,并不需要有操作系统提供运行时支持,所需的一切库都已经在可执行文件里了,因此直接 FROM scratch 会让镜像体积更加小巧。使用 Go 语言 开发的应用很多会使用这种方式来制作镜像,这也是为什么有人认为 Go 是特别适合容器微服务架构的语言的原因之一。
RUN 执行命令
RUN 指令是用来执行命令行命令的。由于命令行的强大能力, RUN 指令在定制镜像时是最常用的指令之一。其格式有两种:
shell 格式:
RUN <命令>,就像直接在命令行中输入的命令一样。例如RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.htmlexec 格式:
RUN ["可执行文件", "参数1", "参数2"],这更像是函数调用中的格式。
RUN 就像 Shell 脚本一样可以执行命令,那么也就可以像 Shell 脚本一样把每个命令对应一个 RUN 。比如:
1 | FROM debian:jessie |
Dockerfile 中每一个指令都会建立一层, RUN 也不例外。每一个 RUN 的行为,都会新建立一层,在此之上执行这些命令,执行结束后, commit 这一层的修改,构成新的镜像。
上面的这种写法,创建了 7 层镜像。这是完全没有意义的,而且很多运行时不需要的东西,都被装进了镜像里,比如编译环境、更新的软件包等等。结果就是产生非常臃肿、非常多层的镜像,不仅仅增加了构建部署的时间,也很容易出错。
Union FS 是有最大层数限制的,比如 AUFS,曾经是最大不得超过 42 层,现在是不得超过 127 层。
上面的 Dockerfile 正确的写法应该是这样:
1 | FROM debian:jessie |
首先,之前所有的命令只有一个目的,就是编译、安装 redis 可执行文件。因此没有必要建立很多层,这只是一层的事情。因此,这里没有使用很多个 RUN 对一一对应不同的命令,而是仅仅使用一个 RUN 指令,并使用 && 将各个所需命令串联起来。将之前的 7 层,简化为了1 层。在撰写 Dockerfile 的时候,要经常提醒自己,这并不是在写 Shell 脚本,而是在定义每一层该如何构建。
并且,这里为了格式化还进行了换行。Dockerfile 支持 Shell 类的行尾添加 \ 的命令换行方式,以及行首 # 进行注释的格式。良好的格式,比如换行、缩进、注释等,会让维护、排障更为容易,这是一个比较好的习惯。
此外,还可以看到这一组命令的最后添加了清理工作的命令,删除了为了编译构建所需要的软件,清理了所有下载、展开的文件,并且还清理了 apt 缓存文件。这是很重要的一步,因为镜像是多层存储,每一层的东西并不会在下一层被删除,会一直跟随着镜像。因此镜像构建时,一定要确保每一层只添加真正需要添加的东西,任何无关的东西都应该清理掉。
构建镜像
回到之前定制的 nginx 镜像的 Dockerfile 来构建这个镜像。在 Dockerfile 文件所在目录执行:
1 | $ docker image build --file ./Nginx-Dockerfile --tag 'nginx:v3' . |
在 Step 3 中,如同之前所说, RUN 指令启动了一个容器 59e17fb13c2b ,执行了所要求的命令,并最后提交了这一层 96de03b40a2f ,随后删除了所用到的这个容器 59e17fb13c2b 。
这里使用了 docker image build 命令进行镜像构建。其格式为:
1 | docker image build [选项] <上下文路径/URL/-> |
在这里指定了最终镜像的名称 --tag nginx:v3 ,构建成功后就可以运行这个镜像了。
镜像构建上下文(Context)
如果注意,会看到 docker image build 命令最后有一个 . ,这个 . 和 ./ 相同,表示的是当前目录。这其实是在指定上下文路径。那么什么是上下文呢?
首先要理解 docker image build 的工作原理。Docker 在运行时分为 Docker 引擎(也就是服务端守护进程)和客户端工具。Docker 的引擎提供了一组 REST API,被称为 Docker Remote API,而 docker 命令这样的客户端工具,则是通过这组 API 与 Docker 引擎交互,从而完成各种功能。因此,虽然表面上好像是在本机执行各种 docker 功能,但实际上,一切都是使用的远程调用形式在服务端(Docker 引擎)完成。也因为这种 C/S 设计,让操作远程服务器的 Docker 引擎变得轻而易举。
当进行镜像构建的时候,并非所有定制都会通过 RUN 指令完成,经常会需要将一些本地文件复制进镜像,比如通过 COPY 指令、 ADD 指令等。而 docker image build 命令构建镜像,其实并非在本地构建,而是在服务端,也就是 Docker 引擎中构建的。那么在这种 客户端/服务端 的架构中,如何才能让服务端获得本地文件呢?
这就引入了上下文的概念。当构建的时候,用户会指定构建镜像上下文的路径, docker image build 命令得知这个路径后,会将路径下的所有内容打包,然后上传给 Docker 引擎。这样 Docker 引擎收到这个上下文包后,展开就会获得构建镜像所需的一切文件。
如果在 Dockerfile 中这么写:
1 | COPY ./package.json /app/ |
这并不是要复制执行 docker image build 命令所在的目录下的 package.json ,也不是复制 Dockerfile 所在目录下的 package.json ,而是复制指定的上下文(context) 目录下的 package.json 。
因此, COPY 这类指令中的源文件的路径不管看上去是相对路径还是绝对路径,其实都是 相对路径,是相对于上下文路径来说的。很多时候,COPY ../package.json /app 或者 COPY /opt/xxxx /app 无法工作,都是因为这些路径已经超出了上下文的范围,Docker 引擎无法获得这些位置的文件。如果真的需要那些文件,应该将它们复制到上下文目录中去。
如果观察 docker image build 输出,其实可以看到这个发送上下文的过程:
1 | $ docker image build --file ./Nginx-Dockerfile --tag 'nginx:v3' ./ |
如此一来,docker image build 就会将该目录下的内容打包交给 Docker 引擎以帮助构建镜像。
理解构建上下文对于镜像构建是很重要的, 可以避免犯一些不应该的错误。 比如有些人在发现 COPY /opt/xxxx /app 不工作后, 于是干脆将 Dockerfile 放到了硬盘根目录去构建, 结果发现 docker image build 执行后, 在发送一个几十 GB 的东西, 极为缓慢而且很容易构建失败。 那是因为这种做法是在让 docker image build 打包整个硬盘, 这显然是错误的用法。
一般情况下,应该将 Dockerfile 置于一个空目录下,或者项目根目录下。如果该目录下没有所需文件,那么应该把所需文件复制一份过来。如果目录下有些东西确实不希望构建时传给 Docker 引擎,那么可以用 .gitignore 一样的语法写一个 .dockerignore ,该文件是用于剔除不需要作为上下文传递给 Docker 引擎的。
那么为什么会有人误以为 . 是指定 Dockerfile 所在目录呢?这是因为在默认情况下,如果不额外指定 Dockerfile 的话,会将上下文目录下的名为 Dockerfile 的文件作为 Dockerfile。
这只是默认行为,实际上 Dockerfile 的文件名并不要求必须为 Dockerfile ,而且并不要求必须位于上下文目录中,比如可以用 --file ../Dockerfile.php 参数指定某个文件作为 Dockerfile 。
其它 docker image build 的用法
- 从 URL 构建,比如可以直接从 Git repo 中构建:
1 | $ docker image build https://github.com/twang2218/gitlab-ce-zh.git\#:8.14 |
这行命令指定了构建所需的 Git repo,并且指定默认的 master 分支,构建目录为 /8.14/ ,然后 Docker 就会自己去 git clone 这个项目、切换到指定分支、并进入到指定目录后开始构建。
- 用给定的 tar 压缩包构建:
1 | $ docker build http://server/context.tar.gz |
如果所给出的 URL 不是个 Git repo,而是个 tar 压缩包,那么 Docker 引擎会下载这个包,并自动解压缩,并把它作为上下文,开始构建。
- 从标准输入中读取 Dockerfile 进行构建:
1 | docker build - < Dockerfile |
如果标准输入传入的是文本文件,则将其视为 Dockerfile ,并开始构建。这种形式由于直接从标准输入中读取 Dockerfile 的内容,它没有上下文,因此不可以像其他方法那样可以将本地文件 COPY 进镜像。
- 从标准输入中读取上下文压缩包进行构建:
1 | $ docker build - < context.tar.gz |
如果发现标准输入的文件格式是 gzip 、 bzip2 以及 xz 的话,将会使其为上下文压缩包,直接将其展开,将里面视为上下文,并开始构建。
Dockerfile 指令详解
COPY 复制文件
格式:
COPY <源路径>... <目标路径>COPY ["<源路径1>", "<源路径2>",... "<目标路径>"]
和 RUN 指令一样,也有两种格式,一种类似于命令行,一种类似于函数调用。COPY 指令将从构建上下文目录中 <源路径> 的文件目录复制到新的一层的镜像内的 <目标路径> 位置。比如:
1 | COPY package.json /usr/src/app/ |
<源路径> 可以是多个,甚至可以是通配符,其通配符规则要满足 Go 的 filepath.Match 规则,如:
1 | COPY hom* /mydir/ |
<目标路径> 可以是容器内的绝对路径,也可以是相对于工作目录的相对路径(工作目录可以用 WORKDIR 指令来指定)。目标路径不需要事先创建,如果目录不存在会在复制文件前先行创建缺失目录。
此外,还需要注意一点,使用 COPY 指令,源文件的各种元数据都会保留。比如读、写、执行权限、文件变更时间等。这个特性对于镜像定制很有用。特别是构建相关文件都在使用 Git 进行管理的时候。
ADD 更高级的复制文件
ADD 指令和 COPY 的格式和性质基本一致。但是在 COPY 基础上增加了一些功能。
比如 <源路径> 可以是一个 URL ,这种情况下,Docker 引擎会试图去下载这个链接的文件放到 <目标路径> 去。下载后的文件权限自动设置为 600 ,如果这并不是想要的权限,那么还需要增加额外的一层 RUN 进行权限调整,另外,如果下载的是个压缩包,需要解压缩,也一样还需要额外的一层 RUN 指令进行解压缩。所以不如直接使用 RUN 指令,然后使用 wget 或者 curl 工具下载,处理权限、解压缩、然后清理无用文件更合理。因此,这个功能其实并不实用,而且不推荐使用。
如果 <源路径> 为一个 tar 压缩文件的话,压缩格式为 gzip , bzip2 以及 xz 的情况下, ADD 指令将会自动解压缩这个压缩文件到 <目标路径> 去。在某些情况下,这个自动解压缩的功能非常有用,比如官方镜像 ubuntu 中:
1 | FROM scratch |
但在某些情况下,如果只是希望复制个压缩文件进去,而不解压缩,这时就不可以使用 ADD 命令了。
在 Docker 官方的 Dockerfile 最佳实践文档 中要求,尽可能的使用 COPY ,因为 COPY 的语义很明确,就是复制文件而已,而 ADD 则包含了更复杂的功能,其行为也不一定很清晰。最适合使用 ADD 的场合,就是所提及的需要自动解压缩的场合。
另外需要注意的是, ADD 指令会让镜像构建缓存失效,从而可能会使镜像构建变得比较缓慢。
因此在 COPY 和 ADD 指令中选择的时候,可以遵循这样的原则,所有的文件复制均使用 COPY 指令,仅在需要自动解压缩的场合使用 ADD 。
CMD 容器启动命令
CMD 指令的格式和 RUN 相似,也是两种格式:
shell格式:CMD <命令>exec格式:CMD ["可执行文件", "参数1", "参数2"...]- 参数列表格式:
CMD ["参数1", "参数2"...]。在指定了ENTRYPOINT指令后,用CMD指定具体的参数。
容器不是虚拟机,说到底就是进程。既然是进程,那么在启动容器的时候,需要指定所运行的程序及参数。CMD 指令就是用于指定默认的容器主进程的启动命令的。
在运行时可以指定新的命令来替代镜像设置中的这个默认命令,比如, ubuntu 镜像默认的 CMD 是 /bin/bash ,如果直接 docker run --interactive --tty ubuntu 的话,会直接进入 bash 。也可以在运行时指定运行别的命令,如 docker run -it ubuntu cat /etc/os-release 。这就是用 cat /etc/os-release 命令替换了默认的 /bin/bash 命令了,输出了系统版本信息。
在指令格式上,一般推荐使用 exec 格式,这类格式在解析时会被解析为 JSON 数组,因此一定要使用双引号 " ,而不要使用单引号。
如果使用 shell 格式的话,实际的命令会被包装为 sh -c 的参数的形式进行执行。比如:
1 | CMD echo $HOME |
在实际执行中,会将其变更为:
1 | CMD [ "sh", "-c", "echo $HOME" ] |
这就是可以使用环境变量的原因,因为这些环境变量会被 shell 进行解析处理。
提到 CMD 就不得不提容器中应用在前台执行和后台执行的问题。Docker 不是虚拟机,容器中的应用都应该以前台执行,而不是像虚拟机、物理机里面那样,用 upstart/systemd 去启动后台服务,容器内没有后台服务的概念。
如果将 CMD 写为:
1 | CMD service nginx start |
然后发现容器执行后就立即退出了。甚至在容器内去使用 systemctl 命令结果却发现根本执行不了。这就是因为没有搞明白前台、后台的概念,没有区分容器和虚拟机的差异,依旧在以传统虚拟机的角度去理解容器。
对于容器而言,其启动程序就是容器应用进程,容器就是为了主进程而存在的,主进程退出,容器就失去了存在的意义,从而退出,其它辅助进程不是它需要关心的东西。
而使用 service nginx start 命令,则是希望 upstart 来以后台守护进程形式启动 nginx 服务。而刚才说了 CMD service nginx start 会被理解为 CMD [ "sh", "-c", "service nginxstart"] ,因此主进程实际上是 sh 。那么当 service nginx start 命令结束后, sh 也就结束了, sh 作为主进程退出了,自然就会令容器退出。
正确的做法是直接执行 nginx 可执行文件,并且要求以前台形式运行。比如:
1 | CMD ["nginx", "-g", "daemon off;"] |
ENTRYPOINT 入口点
ENTRYPOINT 的格式和 RUN 指令格式一样,分为 exec 格式和 shell 格式。ENTRYPOINT 的目的和 CMD 一样,都是在指定容器启动程序及参数。 ENTRYPOINT 在运行时也可以替代,不过比 CMD 要略显繁琐,需要通过 docker run 的参数 --entrypoint 来指定。
当指定了 ENTRYPOINT 后, CMD 的含义就发生了改变,不再是直接的运行其命令,而是将 CMD 的内容作为参数传给 ENTRYPOINT 指令,换句话说实际执行时,将变为:
1 | <ENTRYPOINT> "<CMD>" |
那么有了 CMD 后,为什么还要有 ENTRYPOINT 呢?这种 <ENTRYPOINT> "<CMD>" 有什么好处么?来看几个场景。
场景一:让镜像变成像命令一样使用
假设我们需要一个得知自己当前公网 IP 的镜像,那么可以先用 CMD 来实现:
1 | FROM ubuntu:16.04 |
假如使用 docker image build --file ./Dockerfile.myip --tag myip . 来构建镜像的话,如果需要查询当前公网 IP,只需要执行:
1 | $ docker run myip |
看起来好像可以直接把镜像当做命令使用了,不过命令总会有参数,如果现在希望加参数呢?比如从上面的 CMD 中可以看到实质的命令是 curl ,那么如果现在希望显示 HTTP 头信息,就需要加上 -i 参数。那么可以直接加 -i 参数给 docker run myip 么?
1 | $ docker run myip -i |
可以看到可执行文件找不到的报错, executable file not found 。之前说过,跟在镜像名后面的是 command ,运行时会替换 CMD 的默认值。因此这里的 -i 替换了原来的 CMD ,而不是添加在原来的 curl -s https://ip.cn 后面。而 -i 根本不是命令,所以自然找不到。
如果希望加入 -i 这参数,就必须重新完整的输入这个命令:
1 | $ docker run myip curl -s https://ip.cn -i |
这样就非常不人性化,而使用 ENTRYPOINT 就可以解决这个问题。现在重新用 ENTRYPOINT 来实现这个镜像:
1 | FROM ubuntu:16.04 |
删除之前的残留,重新构建镜像:
1 | $ docker container rm $(docker container ps -a | awk '/myip/{print $1}') |
再次尝试直接使用 -i 选项:
1 | $ docker run myip |
可以看到,这次成功了。这是因为当存在 ENTRYPOINT 后, CMD 的内容将会作为参数传给 ENTRYPOINT ,而这里 -i 就是新的 CMD ,因此会作为参数传给 curl ,从而达到了预期的效果。
场景二:应用运行前的准备工作
启动容器就是启动主进程,但有些时候,启动主进程前,需要一些准备工作。比如 mysql 类的数据库,可能需要一些数据库配置、初始化的工作,这些工作要在最终的 mysql 服务器运行之前解决。
此外,可能希望避免使用 root 用户去启动服务,从而提高安全性,而在启动服务前还需要以 root 身份执行一些必要的准备工作,最后切换到服务用户身份启动服务。或者除了服务外,其它命令依旧可以使用 root 身份执行,方便调试等。
这些准备工作是和容器 CMD 无关的,无论 CMD 是什么,都需要事先进行一个预处理的工作。这种情况下,可以写一个脚本,然后放入 ENTRYPOINT 中去执行,而这个脚本会将接到的参数(也就是 <CMD> )作为命令,在脚本最后执行。比如官方镜像 redis 中就是这么做的:
1 | FROM alpine:3.4 |
可以看到其中为 redis 服务创建了 redis 用户,并在最后指定了 ENTRYPOINT 为 docker-entrypoint.sh 脚本。
1 |
|
该脚本的内容就是根据 CMD 的内容来判断,如果是 redis-server 的话,则切换到 redis 用户身份启动服务器,否则依旧使用 root 身份执行。比如:
1 | $ docker run -it redis id |
ENV 设置环境变量
格式有两种:
ENV <key> <value>ENV <key1>=<value1> <key2>=<value2>...
这个指令很简单,就是设置环境变量而已,无论是后面的其它指令,如 RUN , 还是容器内运行时的应用程序,都可以直接使用这里定义的环境变量。
1 | ENV VERSION=1.0 DEBUG=on \ |
这个例子中演示了如何换行,以及对含有空格的值用双引号括起来的办法,这和 Shell 下的行为是一致的。定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。比如在官方 node 镜像 Dockerfile 中,就有类似这样的代码:
1 | ENV NODE_VERSION 7.2.0 |
在这里先定义了环境变量 NODE_VERSION ,其后的 RUN 这层里,多次使用 $NODE_VERSION 来进行操作定制。可以看到,将来升级镜像构建版本的时候,只需要更新 7.2.0 即可, Dockerfile 构建维护变得更轻松了。
下列指令可以支持环境变量展开:
ADD 、 COPY 、 ENV 、 EXPOSE 、 LABEL 、 USER 、 WORKDIR 、 VOLUME 、 STOPSIGNAL 、 ONBUILD 。
环境变量可以使用的地方很多,通过环境变量,可以让一份 Dockerfile 制作更多的镜像,只需使用不同的环境变量即可。
ARG 构建参数
格式: ARG <参数名>[=<默认值>]
构建参数和 ENV 的效果一样,都是设置环境变量。所不同的是, ARG 所设置的构建环境的环境变量,在将来容器运行时是不会存在这些环境变量的。但是不要因此就使用 ARG 保存密码之类的信息,因为 docker history 还是可以看到所有值的。
Dockerfile 中的 ARG 指令是定义参数名称,以及定义其默认值。该默认值可以在构建命令 docker image build 中用 --build-arg <参数名>=<值> 来覆盖。
在 1.13 之前的版本,要求 --build-arg 中的参数名,必须在 Dockerfile 中用 ARG 定义过了,换句话说,就是 --build-arg 指定的参数,必须在 Dockerfile 中使用了。如果对应参数没有被使用,则会报错退出构建。从 1.13 开始,这种严格的限制被放开,不再报错退出,而是显示警告信息,并继续构建。这对于使用 CI 系统,用同样的构建流程构建不同的 Dockerfile 的时候比较有帮助,避免构建命令必须根据每个 Dockerfile 的内容修改。
VOLUME 定义匿名卷
格式为:
VOLUME ["<路径1>", "<路径2>"...]VOLUME <路径>
容器运行时应该尽量保持容器存储层不发生写操作,对于数据库类需要保存动态数据的应用,其数据库文件应该保存于卷(volume)中。为了防止运行时用户忘记将动态文件所保存目录挂载为卷,在 Dockerfile 中,可以事先指定某些目录挂载为匿名卷,这样在运行时如果用户不指定挂载,其应用也可以正常运行,不会向容器存储层写入大量数据。
1 | VOLUME /data |
这里的 /data 目录就会在运行时自动挂载为匿名卷,任何向 /data 中写入的信息都不会记录进容器存储层,从而保证了容器存储层的无状态化。当然,运行时可以覆盖这个挂载设置。比如:
1 | docker run -d -v mydata:/data xxxx |
在这行命令中,就使用了 mydata 这个命名卷挂载到了 /data 这个位置,替代了 Dockerfile 中定义的匿名卷的挂载配置。
EXPOSE 声明暴露的端口
格式为 EXPOSE <端口1> [<端口2>...]
EXPOSE 指令是声明运行时容器提供的服务端口,这只是一个声明,在运行时并不会因为这个声明应用就会开启这个端口的服务。在 Dockerfile 中写入这样的声明有两个好处,一个是帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射;另一个用处则是在运行时使用随机端口映射时,也就是docker run -P 时,会自动随机映射 EXPOSE 的端口。
此外,在早期 Docker 版本中还有一个特殊的用处。以前所有容器都运行于默认桥接网络中,因此所有容器互相之间都可以直接访问,这样存在一定的安全性问题。于是有了一个 Docker 引擎参数 --icc=false ,当指定该参数后,容器间将默认无法互访,除非互相间使用了 --links 参数的容器才可以互通,并且只有镜像中 EXPOSE 所声明的端口才可以被访问。这个--icc=false 的用法,在引入了 docker network 后已经基本不用了,通过自定义网络可以很轻松的实现容器间的互联与隔离。
要将 EXPOSE 和在运行时使用 -p <宿主端口>:<容器端口> 区分开来。-p ,是映射宿主端口和容器端口,换句话说,就是将容器的对应端口服务公开给外界访问,而 EXPOSE 仅仅是声明容器打算使用什么端口而已,并不会自动在宿主进行端口映射。
WORKDIR 指定工作目录
格式为 WORKDIR <工作目录路径> 。
使用 WORKDIR 指令可以来指定工作目录(或者称为当前目录),以后各层的当前目录就被改为指定的目录,如该目录不存在, WORKDIR 会自动建立目录。
不应该把 Dockerfile 看成是在写 Shell 脚本,因为可能会导致出现下面这样的错误:
1 | RUN cd /app |
如果将这个 Dockerfile 进行构建镜像运行后,会发现找不到 /app/world.txt 文件,或者其内容不是 hello 。原因其实很简单,在 Shell 中,连续两行是同一个进程执行环境,因此前一个命令修改的内存状态,会直接影响后一个命令;而在 Dockerfile 中,这两行 RUN 命令的执行环境根本不同,是两个完全不同的容器。这就是对 Dockerfile 构建分层存储的概念不了解所导致的错误。
每一个 RUN 都是启动一个容器、执行命令、然后提交存储层文件变更。第一层 RUN cd /app 的执行仅仅是当前进程的工作目录变更,一个内存上的变化而已,其结果不会造成任何文件变更。而到第二层的时候,启动的是一个全新的容器,跟第一层的容器更完全没关系,自然不可能继承前一层构建过程中的内存变化。因此如果需要改变以后各层的工作目录的位置,那么应该使用 WORKDIR 指令。
USER 指定当前用户
格式:USER <用户名>
USER 指令和 WORKDIR 相似,都是改变环境状态并影响以后的层。 WORKDIR 是改变工作目录, USER 则是改变之后层的执行 RUN , CMD 以及 ENTRYPOINT 这类命令的身份。当然,和 WORKDIR 一样, USER 只是帮助你切换到指定用户而已,这个用户必须是事先建立好的,否则无法切换。
1 | RUN groupadd -r redis && useradd -r -g redis redis |
如果以 root 执行的脚本,在执行期间希望改变身份,比如希望以某个已经建立好的用户来运行某个服务进程,不使用 su 或者 sudo ,这些都需要比较麻烦的配置,而且在 TTY 缺失的环境下经常出错。建议使用 gosu 。
1 | # 建立 redis 用户,并使用 gosu 换另一个用户执行命令 |
HEALTHCHECK 健康检查
格式:
HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令。HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令。
HEALTHCHECK 指令是告诉 Docker 应该如何进行判断容器的状态是否正常,这是 Docker 1.12 引入的新指令。
在没有 HEALTHCHECK 指令前,Docker 引擎只可以通过容器内主进程是否退出来判断容器是否状态异常。很多情况下这没问题,但是如果程序进入死锁状态,或者死循环状态,应用进程并不退出,但是该容器已经无法提供服务了。在 1.12 以前,Docker 不会检测到容器的这种状态,从而不会重新调度,导致可能会有部分容器已经无法提供服务了却还在接受用户请求。
而自 1.12 之后,Docker 提供了 HEALTHCHECK 指令,通过该指令指定一行命令,用这行命令来判断容器主进程的服务状态是否还正常,从而比较真实的反应容器实际状态。
当在一个镜像指定了 HEALTHCHECK 指令后,用其启动容器,初始状态会为 starting ,在 HEALTHCHECK 指令检查成功后变为 healthy ,如果连续一定次数失败,则会变为 unhealthy 。
HEALTHCHECK 支持下列选项:
--interval=<间隔>:两次健康检查的间隔,默认为 30 秒;--timeout=<时长>:健康检查命令运行超时时间,如果超过这个时间,本次健康检查就被视为失败,默认 30 秒;--retries=<次数>:当连续失败指定次数后,则将容器状态视为unhealthy,默认 3次。
和 CMD , ENTRYPOINT 一样, HEALTHCHECK 只可以出现一次,如果写了多个,只有最后一个生效。
在 HEALTHCHECK [选项] CMD 后面的命令,格式和 ENTRYPOINT 一样,分为 shell 格式,和 exec 格式。命令的返回值决定了该次健康检查的成功与否:0 :成功; 1 :失败; 2 :保留,不要使用这个值。
假设有个镜像是个最简单的 Web 服务,现在希望增加健康检查来判断其 Web 服务是否在正常工作,可以用 curl 来帮助判断,其 Dockerfile 的 HEALTHCHECK 可以这么写:
1 | FROM nginx |
这里为了试验,设置了每 5 秒检查一次,实际应该相对较长,如果健康检查命令超过 3 秒没响应就视为失败,并且使用 curl -fs http://localhost/ || exit 1 作为健康检查命令。
使用 docker image build 来构建这个镜像:
1 | $ docker image build --file ./Dockerfile.mynginx --tag 'mynginx:v1' . |
构建好了后,启动一个容器,并查看状态:
1 | $ docker container run -d --name web01 -p 80:80 mynginx:v1 && docker container ls |
当运行该镜像后,通过 docker container ls 看到最初的状态为 (health: starting) 。在等待几秒钟后,再次 docker container ls ,就会看到健康状态变化为了 (healthy)。如果健康检查连续失败超过了重试次数,状态就会变为 (unhealthy) 。
为了帮助排障,健康检查命令的输出(包括 stdout 以及 stderr )都会被存储于健康状态里,可以用 docker container inspect 来查看。
1 | $ docker container inspect --format '{{json .State.Health}}' web01 | python -m json.tool |
ONBUILD 为他人做嫁衣裳
格式: ONBUILD <其它指令> 。
ONBUILD 是一个特殊的指令,它后面跟的是其它指令,比如 RUN , COPY 等,而这些指令,在当前镜像构建时并不会被执行。只有当以当前镜像为基础镜像,去构建下一级镜像的时候才会被执行。
Dockerfile 中的其它指令都是为了定制当前镜像而准备的,唯有 ONBUILD 是为了帮助别人定制自己而准备的。
假设要制作 Node.js 所写的应用的镜像。而 Node.js 使用 npm 进行包管理,所有依赖、配置、启动信息等会放到 package.json 文件里。在拿到程序代码后,需要先进行 npm install 才可以获得所有需要的依赖。然后就可以通过 npm start 来启动应用。因此,一般情况下,应该这样写 Dockerfile :
1 | FROM node:slim |
把这个 Dockerfile 放到 Node.js 项目的根目录,构建好镜像后,就可以直接拿来启动容器运行。但是如果还有第二个 Node.js 项目也差不多呢?好吧,那就再把这个 Dockerfile 复制到第二个项目里。那如果有第三个项目呢?再复制么?文件的副本越多,版本控制就越困难。
如果第一个 Node.js 项目在开发过程中,发现这个 Dockerfile 里存在问题,比如敲错字了、或者需要安装额外的包,然后开发人员修复了这个 Dockerfile ,再次构建,问题解决。第一个项目没问题了,但是第二个项目呢?虽然最初 Dockerfile 是复制、粘贴自第一个项目的,但是并不会因为第一个项目修复了他们的 Dockerfile ,而第二个项目的 Dockerfile 就会被自动修复。
那么可不可以做一个基础镜像,然后各个项目使用这个基础镜像呢?这样基础镜像更新,各个项目不用同步 Dockerfile 的变化,重新构建后就继承了基础镜像的更新。那么上面的这个 Dockerfile 就会变为:
1 | FROM node:slim |
这里把项目相关的构建指令拿出来,放到子项目里去。假设这个基础镜像的名字为 mynode ,各个项目内的自己的 Dockerfile 就变为:
1 | FROM my-node |
基础镜像变化后,各个项目都用这个 Dockerfile 重新构建镜像,会继承基础镜像的更新。那么,问题解决了么?没有。准确说,只解决了一半。如果这个 Dockerfile 里面有些东西需要调整呢?比如所有的项目中 npm install 都需要加一些参数,这一行 RUN 是不可能放入基础镜像的,因为涉及到了当前项目的 ./package.json ,难道又要一个个修改么?所以说,这样制作基础镜像,只解决了原来的 Dockerfile 的前 4 条指令的变化问题,而后面三条指令的变化则完全没办法处理。
ONBUILD 可以解决这个问题。用 ONBUILD 重新写一下基础镜像的 Dockerfile :
1 | FROM node:slim |
回到原始的 Dockerfile ,这次将项目相关的指令加上 ONBUILD ,这样在构建基础镜像的时候,这三行并不会被执行。然后各个项目的 Dockerfile 就变成了简单地:
1 | FROM my-node |
是的,只有这么一行。当在各个项目目录中,用这个只有一行的 Dockerfile 构建镜像时,之前基础镜像的那三行 ONBUILD 就会开始执行,成功地将当前项目的代码复制进镜像、并且针对本项目执行 npm install ,生成应用镜像。
参考文档
- Dockerfie 官方文档:https://docs.docker.com/engine/reference/builder/
- Dockerfile 最佳实践文档:https://docs.docker.com/engine/userguide/engimage/dockerfile_best-practices/
- Docker 官方镜像 Dockerfile :https://github.com/docker-library/docs
多阶段构建
之前的做法
在 Docker 17.05 版本之前,构建 Docker 镜像时,通常会采用两种方式:
全部放入一个 Dockerfile
一种方式是将所有的构建过程编包含在一个 Dockerfile 中,包括项目及其依赖库的编译、测试、打包等流程,这里可能会带来的一些问题:
- Dockerfile 特别长,可维护性降低
- 镜像层次多,镜像体积较大,部署时间变长
- 源代码存在泄露的风险
例如,编写 app.go 文件,该程序输出 Hello World! :
1 | package main |
编写 Dockerfile.one 文件:
1 | FROM golang:1.9-alpine |
构建镜像
1 | $ docker image build --tag 'go/helloworld:1' --file Dockerfile.one . |
分散到多个 Dockerfile
另一种方式,就是事先在一个 Dockerfile 将项目及其依赖库编译测试打包好后,再将其拷贝到运行环境中,这种方式需要我们编写两个 Dockerfile 和一些编译脚本才能将其两个阶段自动整合起来,这种方式虽然可以很好地规避第一种方式存在的风险,但明显部署过程较复杂。
例如,编写 Dockerfile.build 文件:
1 | FROM golang:1.9-alpine |
编写 Dockerfile.copy 文件:
1 | FROM alpine:latest |
新建 build.sh:
1 |
|
现在运行脚本即可构建镜像:
1 | $ chmod +x build.sh |
对比两种方式生成的镜像大小
1 | $ docker image ls |
使用多阶段构建
从 Docker v17.05 开始支持多阶段构建 ( multistage builds )。使用多阶段构建就可以很容易解决前面提到的问题,并且只需要编写一个 Dockerfile :
例如:
编写 Dockerfile 文件
1 | FROM golang:1.9-alpine |
构建镜像
1 | $ docker build -t go/helloworld:3 . |
对比三个镜像大小
1 | $ docker image ls |
很明显使用多阶段构建的镜像体积小,同时也完美解决了上边提到的问题。
其它制作镜像的方式
除了标准的使用 Dockerfile 生成镜像的方法外,由于各种特殊需求和历史原因,还提供了一些其它方法用以生成镜像。
从 rootfs 压缩包导入
格式: docker import [选项] <文件>|<URL>|- [<仓库名>[:<标签>]]
压缩包可以是本地文件、远程 Web 文件,甚至是从标准输入中得到。压缩包将会在镜像 / 目录展开,并直接作为镜像第一层提交。
比如要创建一个 OpenVZ 的 Ubuntu 14.04 模板 的镜像:
1 | $ docker import \ |
这条命令自动下载了 ubuntu-14.04-x86_64-minimal.tar.gz 文件,并且作为根文件系统展开导入,并保存为镜像 openvz/ubuntu:14.04 。
导入成功后,可以看到这个导入的镜像:
1 | $ docker image ls openvz/ubuntu |
如果查看其历史的话,会看到描述中有导入的文件链接:
1 | $ docker history openvz/ubuntu:14.04 |
docker save 和 docker load
Docker 还提供了 docker load 和 docker save 命令,用以将镜像保存为一个 tar 文件,然后传输到另一个位置上,再加载进来。这是在没有 Docker Registry 时的做法,现在已经不推荐,镜像迁移应该直接使用 Docker Registry,无论是直接使用 Docker Hub 还是使用内网私有 Registry 都可以。
保存镜像
使用 docker save 命令可以将镜像保存为归档文件。比如保存 ubuntu 镜像:
1 | $ docker image ls ubuntu |
保存镜像的命令为:
1 | $ docker image save ubuntu | gzip > ubuntu-latest.tar.gz |
然后将 ubuntu-latest.tar.gz 文件复制到到了另一个机器上,用下面这个命令加载镜像:
1 | $ docker load -i ubuntu-latest.tar.gz |
镜像的实现原理
Docker 镜像是怎么实现增量的修改和维护的?
每个镜像都由很多层次构成,Docker 使用 Union FS 将这些不同的层结合到一个镜像中去。
通常 Union FS 有两个用途, 一方面可以实现不借助 LVM、RAID 将多个 disk 挂到同一个目录下,另一个更常用的就是将一个只读的分支和一个可写的分支联合在一起,Live CD 正是基于此方法可以允许在镜像不变的基础上允许用户在其上进行一些写操作。
Docker 在 AUFS 上构建的容器也是利用了类似的原理。
访问仓库
仓库( Repository )是集中存放镜像的地方。
一个容易混淆的概念是注册服务器( Registry )。实际上注册服务器是管理仓库的具体服务器,每个服务器上可以有多个仓库,而每个仓库下面有多个镜像。从这方面来说,仓库可以被认为是一个具体的项目或目录。例如对于仓库地址 dl.dockerpool.com/ubuntu 来说, dl.dockerpool.com 是注册服务器地址, ubuntu 是仓库名。
大部分时候,并不需要严格区分这两者的概念。
Docker Hub
目前 Docker 官方维护了一个公共仓库 Docker Hub,其中已经包括了数量超过 15,000 的镜像。大部分需求都可以通过在 Docker Hub 中直接下载镜像来实现。
注册
可以在 https://hub.docker.com/signup 免费注册一个 Docker 账号。
登录
可以通过执行 docker login 命令交互式的输入用户名及密码来完成在命令行界面登录 Docker Hub。通过 docker logout 退出登录。
拉取镜像
通过 docker search 命令来查找官方仓库中的镜像,并利用 docker pull 命令来将它下载到本地。
例如以 centos 为关键词进行搜索:
1 | $ docker search centos |
可以看到返回了很多包含关键字的镜像,其中包括镜像名字、描述、收藏数(表示该镜像的受关注程度)、是否官方创建、是否自动创建。
官方的镜像说明是官方项目组创建和维护的,automated 资源允许用户验证镜像的来源和内容。
根据是否是官方提供,可将镜像资源分为两类。
一种是类似 centos 这样的镜像,被称为基础镜像或根镜像。这些基础镜像由 Docker 公司创建、验证、支持、提供。这样的镜像往往使用单个单词作为名字。
还有一种类型,比如 tianon/centos 镜像,它是由 Docker 的用户创建并维护的,往往带有用户名称前缀。可以通过前缀 username/ 来指定使用某个用户提供的镜像,比如 tianon 用户
另外,在查找的时候通过 --filter=stars=N 参数可以指定仅显示收藏数量为 N 以上的镜像。
下载官方 centos 镜像到本地。
1 | $ docker pull centos |
推送镜像
用户也可以在登录后通过 docker push 命令来将自己的镜像推送到 Docker Hub。以下命令中的 username 请替换为你的 Docker 账号用户名。
1 | $ docker tag ubuntu:17.10 username/ubuntu:17.10 |
自动创建
自动创建(Automated Builds)功能对于需要经常升级镜像内程序来说,十分方便。
有时候,用户创建了镜像,安装了某个软件,如果软件发布新版本则需要手动更新镜像。
而自动创建允许用户通过 Docker Hub 指定跟踪一个目标网站(目前支持 GitHub 或 BitBucket )上的项目,一旦项目发生新的提交或者创建新的标签(tag),Docker Hub 会自动构建镜像并推送到 Docker Hub 中。
要配置自动创建,包括如下的步骤:
创建并登录 Docker Hub,以及目标网站;
在目标网站中连接帐户到 Docker Hub;
在 Docker Hub 中 配置一个自动创建;
选取一个目标网站中的项目(需要含 Dockerfile )和分支;
指定 Dockerfile 的位置,并提交创建。
之后,可以在 Docker Hub 的 自动创建页面中跟踪每次创建的状态。
私有仓库
有时候使用 Docker Hub 这样的公共仓库可能不方便,用户可以创建一个本地仓库供私人使用。
docker-registry 是官方提供的工具,可以用于构建私有的镜像仓库。
安装运行 docker-registry
安装运行 docker-registry 可以通过获取官方 registry 镜像来运行。
1 | $ docker run -d -p 5000:5000 --restart=always --name registry registry |
这将使用官方的 registry 镜像来启动私有仓库。默认情况下,仓库会被创建在容器的 /var/lib/registry 目录下。可以通过 -v 参数来将镜像文件存放在本地的指定路径。例如下面的例子将上传的镜像放到本地的 /opt/data/registry 目录。
1 | $ docker run -d \ |
在私有仓库上传、搜索、下载镜像
创建好私有仓库之后,就可以使用 docker tag 来标记一个镜像,然后推送它到仓库。例如私有仓库地址为 127.0.0.1:5000 。
先在本机查看已有的镜像。
1 | $ docker image ls ubuntu |
使用 docker tag 将 ubuntu:latest 这个镜像标记为 127.0.0.1:5000/ubuntu:latest 。
格式为 docker tag IMAGE[:TAG] [REGISTRY_HOST[:REGISTRY_PORT]/]REPOSITORY[:TAG] 。
1 | $ docker tag ubuntu:latest 127.0.0.1:5000/ubuntu:latest |
使用 docker push 上传标记的镜像。
1 | $ docker push 127.0.0.1:5000/ubuntu:latest |
用 curl 查看仓库中的镜像。
1 | $ curl 127.0.0.1:5000/v2/_catalog |
这里可以看到 {"repositories":["ubuntu"]} ,表明镜像已经被成功上传了。先删除已有镜像,再尝试从私有仓库中下载这个镜像。
1 | $ docker image rm 127.0.0.1:5000/ubuntu:latest |
注意事项
如果不想使用 127.0.0.1:5000 作为仓库地址,比如想让本网段的其他主机也能把镜像推送到私有仓库。就得把例如 192.168.199.100:5000 这样的内网地址作为私有仓库地址,这时会发现无法成功推送镜像。
这是因为 Docker 默认不允许非 HTTPS 方式推送镜像。可以通过 Docker 的配置选项来取消这个限制,或者配置能够通过 HTTPS 访问的私有仓库。
- Ubuntu 14.04, Debian 7 Wheezy
对于使用 upstart 的系统而言,编辑 /etc/default/docker 文件,在其中的 DOCKER_OPTS 中增加如下内容:
1 | DOCKER_OPTS="--registry-mirror=https://registry.docker-cn.com --insecure-registries=192.168.199.100:5000" |
重新启动服务。
1 | $ sudo service docker restart |
- Ubuntu 16.04+, Debian 8+, centos 7
对于使用 systemd 的系统,请在 /etc/docker/daemon.json 中写入如下内容(如果文件不存在需要新建该文件):
1 | { |
文件必须符合 json 文件规范,否则 docker 服务将无法启动。
1 | systemctl restart docker |

